
- Central role of data in DePIN rewards
- Challenges of DePIN data management
- Who owns the data?
- Evolution of data in DePINs
- Kamu: Decentralized data middleware
- Takeaway
Decentralized Physical Infrastructure Networks (DePINs) emerged from decentralized finance as incredible new mechanisms of incentives that enable large groups of people to collectively provide valuable and cohesive services to the society with minimal intermediation and transparent rewards.
Central role of data in DePIN rewards #︎
Data plays central role in DePINs:
-
Some DePINs are purpose-built to crowd-source data collection and reward their contributors based on volume and quality of data (e.g. weather, traffic, air and sound pollution networks, wearable personal health devices)
-
Other DePINs collect data for quality of service purposes (e.g. wireless connectivity providers and idle CPU/GPU compute sharing networks collect node uptime, reliability, and units of work metrics).
In both cases data is the source of truth for determining how much rewards contributors earn for providing their services to the network. Therefore validity of data and computations is of utmost importance to fair token distribution.
Challenges of DePIN data management #︎
Managing data is hard, even in a centralized setting. Tech companies retain large data engineering teams for the sole purpose of making sense of internal data. For DePINs this challenge is even more severe:
-
They often deal with large volumes of device data (IoT), often beyond what a single database can handle.
-
Their analytics and rewards involve combining on-chain and off-chain data, creating a lot of extra work to index data from blockchains and get data into smart contracts.
-
DePINs create value from data only when it crosses organizational boundaries, when it is provided to business consumers, or when it’s shared with data science communities, thus requiring a lot more infrastructure around dissemination APIs and data privacy.
So DePINs need to build a lot more complex tech stack, often on a short budget, while also facing transparency and verifiability pressure that their Web2 counterparts do not.
Who owns the data? #︎
As the result of these challenges, many DePINs fail to deliver on decentralization promisses. By building on top of Web2 data solutions like AWS, Snowflake, BigQuery they re-centralize the data, contraty to their ethos.
You may argue that DePIN data stored this way still can be traced back to the person/device who provided it via device IDs and wallet accounts, but here’s a simple “ownership test”:
If a company behind a DePIN doesn’t pay its server bill - the data of the entire network can be lost, the token value can tank, and years of contributions of people and their hard-earned rewards wiped out in an instant.
The reason for all this is simple: while blockchains mostly solved the decentralization of money, the problem of decentralization of data is largely unsolved.
Evolution of data in DePINs #︎
Most DePIN companies do try hard to deliver on their promises to the community using best tool and resources at their disposal.
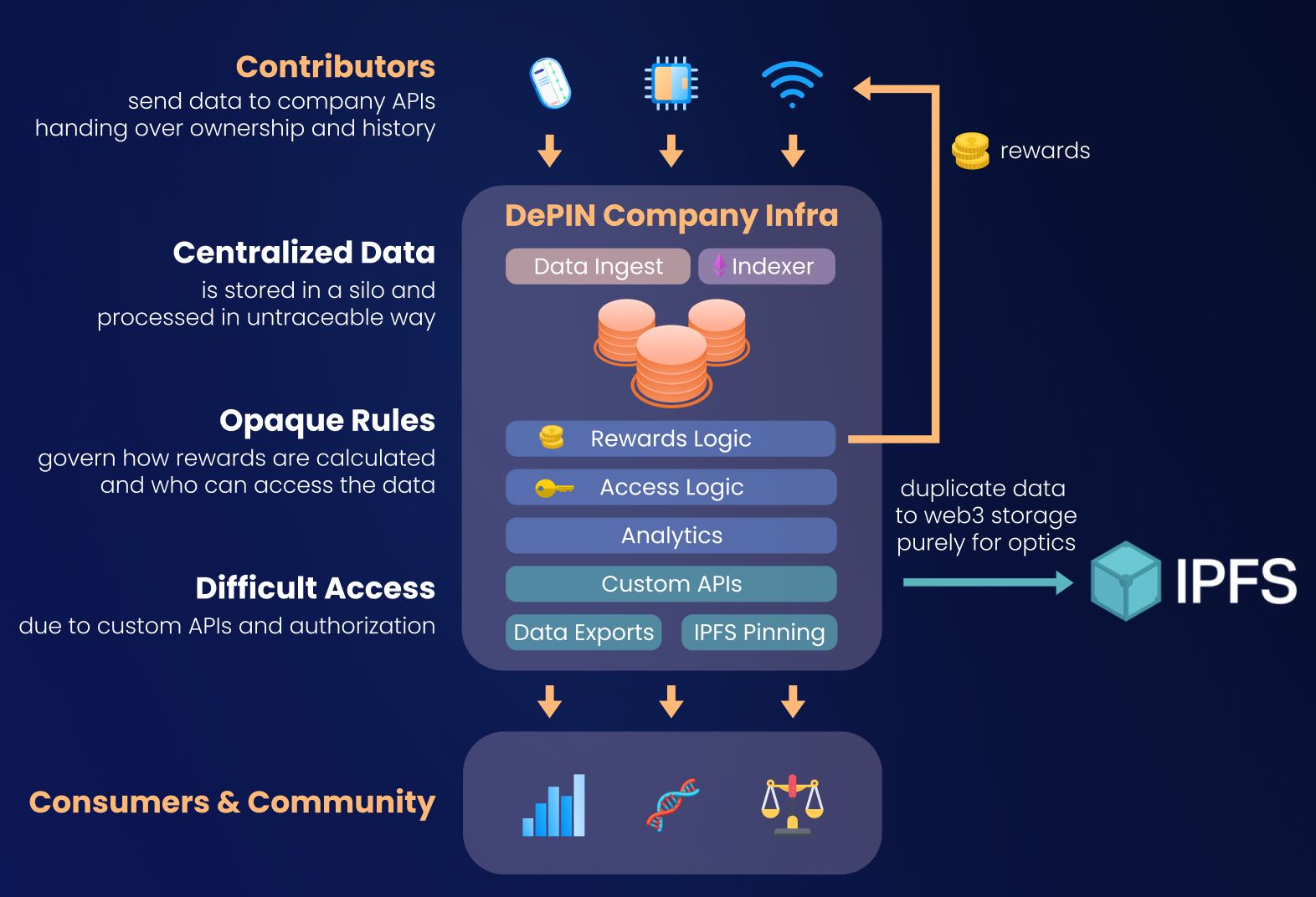
Infrastructure of a typical DePIN with high degree of centralization
Typical evolution stages of data management in such companies may look like this:
- Start collecting data into a single database as a proof of concept
- Write scripts to distribute rewards to early adopters, without any transparency or verifiability
- Build custom APIs to deliver data to first customers, monetize data, and close the value loop
- Develop an interim solution to scale beyond one database, such as offloading historical data to a Parquet data lake in S3
- Develop custom data exports to distribute data to the community for hackathons and challenges to unlock more interesting use cases for their data
- Under pressure to differentiate themselves from Web2 companies they may start pinning data in IPFS or Filecoin.
This is a long and winding path, it takes many years and millions in engineering resources to execute, yet still doesn’t lead to satisfactory results. Having data pinned in IPFS doesn’t solve the underlying re-centralization issues, only masks them under the disguise of duplicating data into a Web3 storage.
By that time data has already lost its verifiability properties and its connection to who provided it, and all data pipelines - the arteries that transport and refine data into more valuable forms - remain proprietary, impossible to reproduce.
Kamu: Decentralized data middleware #︎
Kamu achieves what we used to think was impossible:
- It flips the data management model upside-down, re-focusing it on personal data ownership
- But does so in a way that is non-disruptive and maximally compatible with existing data tools.
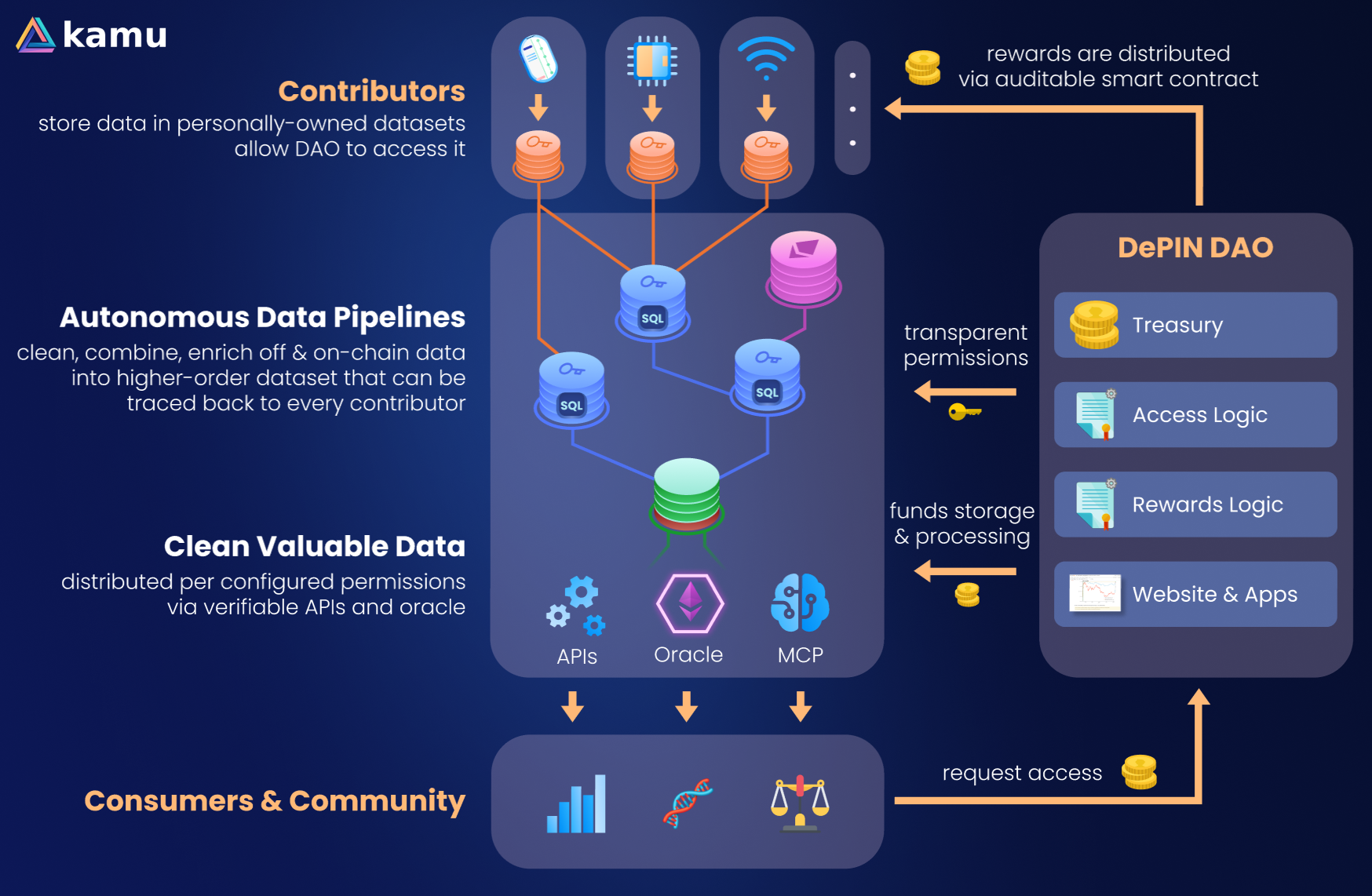
DePIN negotiates access to personally-owned data and refines it via decentralized pipelines
Here’s how it works:
-
People or devices write data into datasets that they own and control. This data can be a high-frequency stream like IoT and reside in any storage of their choice.
-
Kamu stores data as a ledger where information about ownership is inseparable from data, simultaneously protecting data owners from the copy problem and holding them accountable for data they provide.
-
DePIN networks don’t own source data - they are simply granted access to personally-owned datasets.
-
DePINs combine and aggregate real-time data from contributors by creating “views” or derivative datasets that can be queried as efficiently as in centralized infrastructure, but preserve the link to source data throughout all transformations.
-
Through series of verifiable computing pipelines they refine raw data into higher-order valuable datasets and calculate data quality scores of every contributor in a fully transparent way.
-
They monetize high-quality data through smart contracts and grant access permissions to 3rd parties, simultaneously creating a financial trace and an access audit log.
-
In another smart contract they query monetization records in combination with data quality scores to fairly distribute token rewards. By doing this on-chain using Kamu’s verifiable oracle they link every token disbursment to the exact data it was based on, ensuring complete transparency, reproducibility, and auditability.
In the same way as DePINs rely on L1 blockchain networks for decentralized financial services - Kamu provides decentralized data storage and processing services that cover most needs of DePIN infrastructure.
This approach unlocks a dazzling number of cool properties:
-
Refined datasets, business reports, trained AI models - all artifacts can be forever linked to data from verifiable pipelines and the information about who contributed every data point.
-
Verifiable provenance provides the mechanism to both fairly reward everyone who contributed data and maintained the pipelines and to hold everyone accountable for their actions.
-
If DePIN company dissolves - data contributors don’t lose their data. They can take their data elsewhere, or even pool up with data consumers and keep all pipelines running as before. It’s an absolutely crucial step towards making DePINs actually behave like true DAOs.
-
Same devices can be contributing data to multiple DePIN networks at once, earning multiple rewards, without duplicating data.
-
DePIN projects can manage data with full transparency and engage community to contribute towards improving pipelines as easily as they would contribute to an open-source code.
🤔 Interested how all this works? See our DePIN mini-course 🤔
Takeaway #︎
Many early-stage DePINs severely underestimate the challenges of data management at scale. They tie up significant engineering resources towards building highly-custom internal data platforms and end up with high degree of centralization that contradicts their ethos.
We attribute this primarily to lack of Web3-native data tools in the past.
At Kamu we built the first data middleware that can both stand up to most challenges of scale, and allow DePINs skip this long winding path altogether and from day one start building with tools that are purpose-made to enable decentralization and personal data ownership.
We believe it’s a major step that will shift DePIN space closer to operating as DAOs, allow them to more effectively engage their communities, unlock more value from data globally, and let us rebuild the global data economy around tightly aligned incentives.
See Also #︎
- Introduction to Web3 data - a mini-course exemplifying decentralization of DePIN data.
- Oracle-Augmented Generation - how Kamu connects AI agents to real-time verifiable data.
- Next Decade of Data - our view of the upcoming transformation towards global data economy.


