kamu is the new generation data management tool that connects data publishers and consumers worldwide via decentralized data pipeline, and allows people to collaborate on cleaning, transforming, and enriching data (quick introduction).
Today I’ll touch on one of the key design decisions of kamu - how data gets processed.
I’ll explain why we completely rejected batch processing, and why we believe that in 5 years from now stream processing will dominate the majority of data processing use cases.
Batch Processing #︎
Batch needs no introduction - all of you have worked with one type of batch processing or another, be it in Pandas, Hadoop, or Spark, or when you execute any database query, or even when creating an Excel report.
Batch processing is at the core of nearly all of our everyday workflows: generating monthly payrolls, company performance reports, national statistics, research data analysis. AI & machine learning is most often a form of batch processing too. It’s ubiquitous.
The key characteristic of batch is that it requires you to pick a subset of data to operate on (note that “all data” is still a subset if your datasets change over time).
This might be suitable for end-of-cycle processing like payrolls, where at a certain point each month you have all the information you need to generate the result, but this line gets blurry quite fast.
Take US employment situation reports as an example. They are being released monthly, but what cycle dictates that? How many times have we seen this and other major economic reports create dramatic swings in the stock market? Leading up to the release we even see the market “betting” on what the report will look like.
So why can’t we release this data more often, weekly, or daily? Can’t we have this data always available and up-to-date?
Well, turns out the shorter your cycle is the more problematic batch processing becomes. Let’s see why.
Stream Processing #︎
Stream processing has the shortest cycle possible - processing is done as soon as new data arrives. It’s most often used in near-real-time data flows like monitoring & alerting, user analytics, advertising, algorithmic trading, etc.
Its key characteristic is minimal latency. But this great property also exposes it to a whole set of difficult problems:
- Data arriving late
- Data arriving out-of-order
- Corrections to data emitted previously
- Different data arrival cadences
Last one means when you join two data streams together so you may need to delay the processing of one stream before data on another stream arrives, otherwise you will get incorrect results.
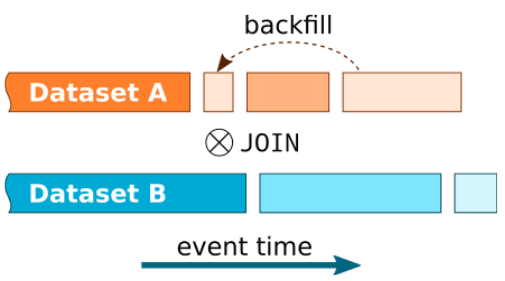
Stream-to-Stream Join
Thankfully, there are many techniques for dealing with these problems:
- Event-time processing allows us to write computations as if data arrived perfectly in order
- Watermarks allow us to account for a possible delay in data and differences in cadences when joining streams
- Windowing lets us aggregate data in a stream
- Triggers let us control when and how results are produced
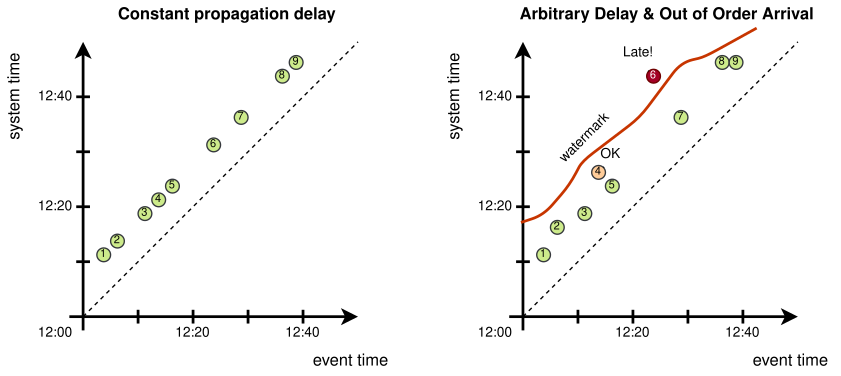
Event-time Processing with Watermarking
Check out The World Beyond Batch: Streaming 101 for more information.
The point is - we have already developed a mature apparatus to easily express computations over streaming data and can let technology deal with the edge cases.
Batch is the Latency and Correctness Killer #︎
The absolute key thing to understand here:
All of these problems are still present in batch!
Depending on which subset of a data you use, you can still have gaps in data or a mismatch of “how far” the two datasets you’re joining have progressed.
Batch processing is when you wait and hope that the data consistency issues disappear on their own. The longer you wait - the better your chances.
The consequence of that is huge latency. And I’m not even talking about the latency introduced by re-processing all data. Even if you had an infinitely fast computer that can re-process all data in an instant - batch would still have significant inherent latency.
The closer you get to the latest data with the batch - the more likely you’ll get incorrect results. As the latest data haven’t “settled” yet, a correction or a backfill may throw your results way off. Your options are to either accept the inaccuracies or add some safety buffer e.g. not using data newer than N days.
For the same reasons batch workflows need to be “babied” - constantly looked after. Whenever there’s a realization that a large amount of data didn’t make it in time for the monthly performance report and needed to be backfilled, or that there was an important correction - it’s up to you, the human, to make this connection and issue a corrected report. That’s a lot of extra cognitive load that further motivates you to increase the mentioned safety buffer.
The latency adds up fast, as well as the probability of inaccuracies that will never be corrected.
If we want data to flow fast between publishers and consumers, want always up-to-date reports and dashboards and them to be correct - batch is the wrong tool for the job.
The Kamu Way #︎
Previously we’ve looked at different approaches to modelling data in OLTP and OLAP, saw how the two worlds are converging on temporal data, and how kamu builds on these ideas and stores data as immutable append-only streams of events.
Designing how data processing will work was one of our hardest challenges.
We anchored ourselves fully in this guiding principle:
Frequency with which data is presented to consumers should be optimized for their experience and usability, not dictated by limitations of the data pipeline.
Meaning that approach we chose had to be:
- Zero-maintenance - allowing people to define transformations once and let the system do the rest
- Low latency - we wanted data to flow through the system in near-real-time
- 100% reproducible - as this is how we ensure that data remains trustworthy as it changes multiple hands when flowing through the pipeline.
All attempts to get these qualities from batch processing have failed, as it involved a constant balancing act between correctness and latency that keeps humans closely in the loop.
Stream processing ticked all these boxes. It took us some time to realize that it’s much more than a tool for low-latency data flows - it’s a more general mathematical model of processing!
If you were to implement a batch processing algorithm that accounts for all the problems of “unsettled” data - you’d be to a large extent reinventing stream processing.
The benefits of streaming in kamu include:
- Users can define a query once and potentially run it forever - this keeps humans out of the loop and minimizes latency.
- Streaming queries are expressive and are closer to “which question is being asked” as opposed to “how to compute the result”. They are usually much more concise than equivalent batch queries.
- Queries can be expressed in a way that is agnostic of how and how often the new data arrives. Whether the data is ingested once a month in Gigabyte batches, in micro-batches every hour, or as a true near-real-time stream - processing logic can stay the same, produce the same results, and guarantee the best propagation times possible.
- Streaming queries are declarative, while batch processing is usually imperative. Declarative nature lets us perform static analysis of queries and automatically derive provenance in many cases without tracking any extra data.
- High-level abstractions like windowing, watermarks, and triggers allow streaming queries to be significantly less error-prone to write than equivalent batch operations.
Going back to our payroll example, using stream processing allows us to express it as a windowed computation which will run automatically with no human involvement, and automate not only the “happy path” but also express how late data and corrections should be handled.
We strongly believe that replacing semi-manual batch-oriented workflows with stream processing can bring several orders of magnitude improvements to data quality, recency, and correctness!
Implementation #︎
The implementation still leaves more to be desired - the technology in this space is still very young, and despite picking the two most mature open-source implementations of streaming available - Apache Spark and Apache Flink - we still encounter many issues.
The streaming SQL dialects, however, pleasantly surprised us with how easy it was to start writing streaming queries for people who only had experience with batch SQL.
Here’s an example of a late shipment detection query using a stream-to-stream join, showing how similar and intuitive it is:
|
|
These dialects are unfortunately not standardized and look very different between the engines (KSQL, Flink, Spark, Storm, WSO2…). The closest thing to a standardization attempt for streaming SQL we’ve seen so far is the Apache Calcite project, so we’re hoping for its wider community adoption and continuation of efforts to standardize the streaming SQL.
Conclusion #︎
The world has already realized that batch processing is just a special case of streaming. In Kamu we’re trying to show how harmful and debilitating this special case is. How it creates latency, sacrifices correctness, and burdens people with repetitive tasks.
While major Big Data vendors are continuing to perfect the batch processing technologies - this only gets us deeper into the local optima. Batch had many decades to show us what it can do, and it failed to deliver.
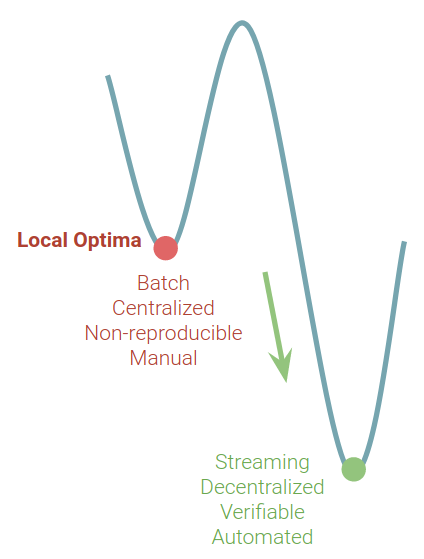
Local Optima of Batch Processing
Data does not originate in batches, nor it changes over time. Data is a record of observations, our modern-age history book, which only gets refined and corrected over time.
Data science community needs to embrace the challenges of temporal data processing - it’s a harder problem to solve, but also the right one.
Immutable data, complete history, full reproducibility, and stream processing might not be suitable in all cases, but we believe this is the most complete data processing model we have so far. Unless you start with the most complete model - you will inevitably end up sacrificing properties that you didn’t actually mean to give up. We know that it’s bad to optimize prematurely, but what’s worse is “optimizing” unknowingly.
Thanks for reading, see you in the next update!