This is a celebratory update as kamu project turns 3 years old this month!🎉
What’s kamu? #︎
Imagine if every small organization and every individual in the world could become a data publisher in just a few minutes:
- At a minimal cost
- Without needing to move or lose ownership of their data
- Able to produce data that flows continuously, in near real-time
- And follow the best data sharing practices without having to know what they are
This data, flowing from from millions of decentralized sources, is then picked up by organizations, data science communities, and enthusiasts:
- Who build multi-stage pipelines that extract insight from raw data
- Who collaborate on data cleaning, enrichment, and harmonization just like on Open Source Software
- Who create data supply chains that work autonomously and with low latency
- And where any doubts about trustworthiness and provenance of data can be resolved in minutes
This refined information and insights is then consumed by government officials, researchers, and journalists:
- To be presented to decision-makers on always up-to-date dashboards
- Used as reproducible input data with verifiable provenance for science projects and AI/ML model training
- And as the source of truth for automation and smart contracts
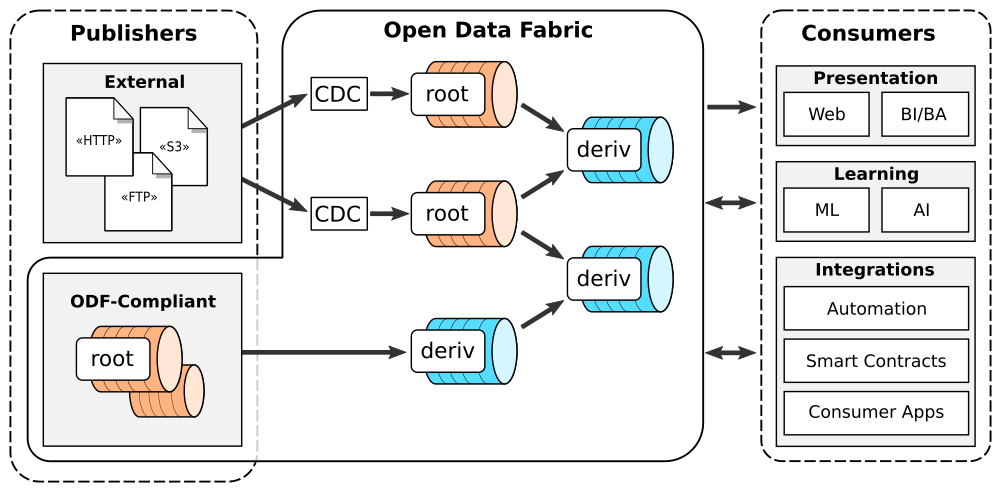
This is the vision of kamu and we have a solid plan to get there, as we are building the world’s first decentralized real-time data warehouse disguised as a command line tool you can run on a laptop.
What’s new? #︎
This update will show what we’ve been up to in the past 6 months.
If you like what we’re doing - please star our repo and spread the word, it helps a lot!
New Documentation Portal #︎
Our docs have a new home: https://docs.kamu.dev
This is the best place to get started with the project and will gently guide you throu the process of getting to know our tooling.
The docs are rendered with hugo and of course remain open-source and easy to contribute to.
Tutorials, Talks, and Examples #︎
To see kamu in action - start with this new YouTube playlist. It covers the basic functionality and then dives into deeper topics, such as trustworthiness of data and (WIP) benefits of stream processing.
We have also presented at PyData Global 2021 recently - check out this talk to understand some theory behind kamu’s ledger-like data and metadata in the context of many decades of evolution of data modelling and processing.
Links to this and many other talks can be found on our Learning Materials page.
Demo! #︎
If you’d like to give kamu a try - check out our Self-serve Demo. It will guide you through many features of the tool without you needing to install anything.
ODF Whitepaper #︎
We have just released in open access the original Open Data Fabric protocol whitepaper - it’s a great introduction to the problems we are solving and the vision we’re working towards.
New Features #︎
We’ve been packing kamu with new features working towards an MVP:
The kamu verify <dataset-id> command is a huge step on our way to trustworthiness of data. It allows you to verify that the data you have downloaded from someone else have not been tampered, and that derivative data was in fact produced by the transformation declared in the metadata (see video tutorial).
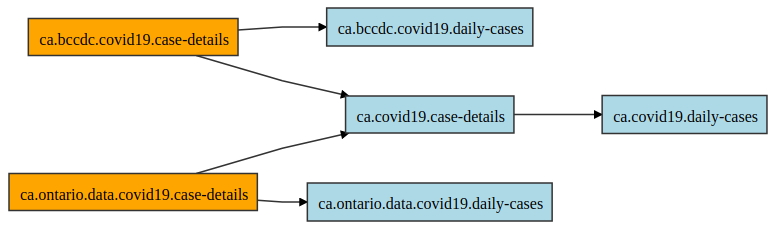
The kamu inspect lineage -b command shows the dependency graph of your datasets in a browser:
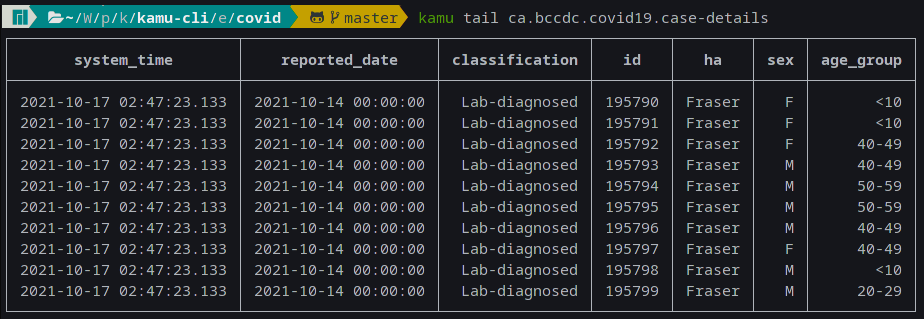
New kamu tail <dataset-id> command allows you to quickly preview last events in a dataset:
The tail command is made possible through integration of the DataFusion SQL engine based on Apache Arrow project. This engine is really fast compared to the startup time of Apache Spark, so we expect to use it more for exploratory data analysis features of kamu in the future.
For ad-hoc querying you can use datafusion as an alternative backend for kamu sql command (see kamu sql --help). It has some missing functionality (e.g. does not support computations on DECIMAL data types) so we cannot make in the default yet, but the community around it is very active and we’re also contributing fixes to make it better. The future of data processing in Rust looks very promising.
Join Us #︎
If you are passionate about data, open-source software, data science, and want to take part in revolutionizing the data exchange worldwide - let’s collaborate!
We have recently set up a Discord server where you can chat with us and other like-minded people about anything data-related.
See you in the next update!