Next week, Kamu is turning 3 years old! 🎉
When we set out to build the “world’s first global data supply chain” we didn’t expect it to be easy … and it’s not. For the last 7 months we had to channel all our resources into things that help us survive as a company: customers, product, and fundraising, so despite the lack of public updates we were hard at work.
Funding secured #︎
Our efforts paid off - the Kamu project has secured more funding!
Addressing systemic issues of data economy might seem akin to a “hot startup”, but in reality, the Enterprise and Web3 Data markets have grown so complex that few possess a clear perspective on them anymore. Building something outside the established buckets (like data lake, catalog, indexer, oracle) and pursuing a fundamental shift also means “big risks” for investors. If very few are properly equipped to assess these risks, even fewer are willing to take them during the market downturn.
We are deeply grateful to exceptional people in Revere, Protocol Labs, Faber, and Gagra Ventures for taking the time to understand us, for sharing our vision and for believing in our ability to bring it to life.
And a very special thanks to Dell Technologies, Infinity, the University of Groningen, and other members of the “Open Data for Data Science” consortium for their support and for connecting us with so many scientists, field experts, research institutes, and companies.
Growing the team #︎
We not only have the means to keep moving forward but can also finally expand our team!
When members of our community were asking about working with us we previously had nothing to offer. “We worked without a salary for 2 years - join us!” was not the job pitch I ever wanted to give. Things are changing now!
We are now looking for exceptional people in three key areas:
- Data Eng (Arrow, DataFusion, Spark, Flink, blockchains) - to work on our novel data formats, protocols, and data engines for verifiable and privacy-preserving data processing.
- Backend (Rust, Kubernetes, multi-cloud) - to work on our decentralized data network and its supporting services
- Frontend (Angular, GraphQL, data viz) - help us build the first collaborative data processing platform, a “GitHub for Data Pipelines”
Technology updates #︎
CLI Tool #︎
kamu-cli was released in early 2021 as a technology prototype that made (still very novel) stream processing far more accessible and combined it with blockchain-like provenance and verifiability.
We were pleasantly surprised that our tool attracted the attention of a very experienced and technical crowd. So many CTOs, CDOs, and experts from fields like science, healthcare, finance, insurance, and web3 gave it a try. Thank you all for your feedback!
Our plan is to continue to evolve kamu-cli into a powerful “Swiss army knife” for data flows - a new alternative to “data-as-code” tools like dbt that takes an opinionated approach to how data should be managed internally and externally for us to achieve:
- Provenance and accountability
- Superior automation and data consistency at low latencies
- Collaborative data cleaning and aggregation
- And other foundational pieces of reproducible science and functioning data economy.
Compute Node #︎
We are now working to evolve the technology you see in the tool into a “deploy-anywhere” data processing service.
Kamu Compute Node is a set of Kubernetes-native applications that can be deployed in any cloud or on-prem to:
- Operate the stream processing pipelines for a certain set of data flows
- Continuously verify datasets that you are interested it to catch malicious behavior
- Serve ad-hoc batch queries and Oracle queries for ingesting data into smart contracts.
Compute nodes are the building pieces of the Open Data Fabric network. Unlike blockchain nodes that maintain a single ledger, Kamu compute nodes can form loosely connected clusters based on the vested interest of their operators in certain types of data.
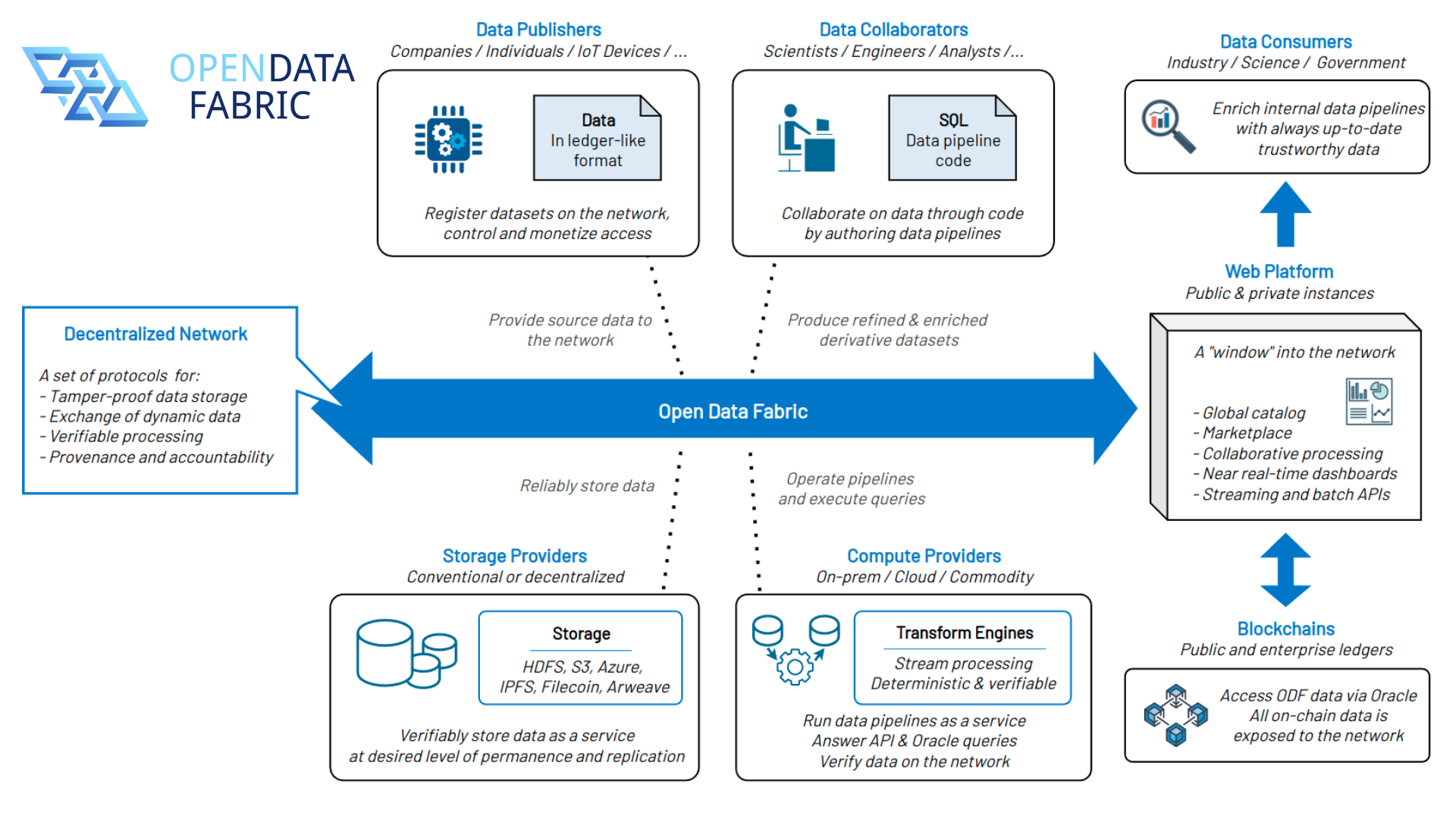
Roles in ODF network
Rather than a flat peer-to-peer, it’s a federated network where:
- A university that cares about the reproducibility of science can contribute storage resources to replicate research datasets,
- A government can provide compute resources to keep civic healthcare data pipelines running, or
- A company using crowdsourced weather data can dedicate resources to continuously verify these communal data pipelines to detect malicious actors.
Our work so far was focused on:
- Helm charts - making it easy to install the node in Kubernetes
- Closer S3 and IPFS integration - making our engines read and transform externally-hosted data while minimizing the data transfers
- Multi-tenancy, authentication, authorization
- Work scheduling, capacity control, and backpressure.
As with the rest of our tech, all code is open, and under a time-delayed Apache license which is free to use from the get-go for almost any organization.
Web Interface #︎
We are continuing to build a “window” into the Open Data Fabric network.
You can think of it as a mix of:
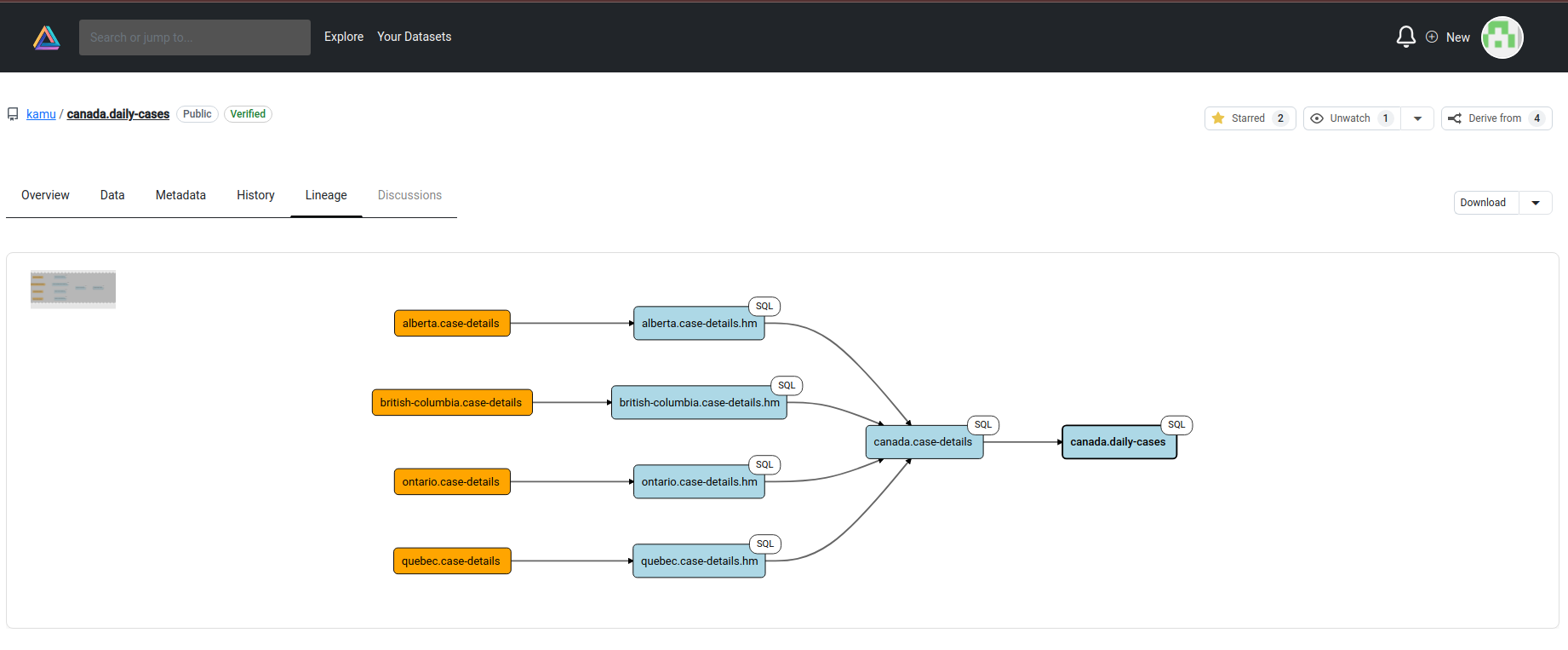
- GitHub - as a place for discovering, collaborating, and governance of data:
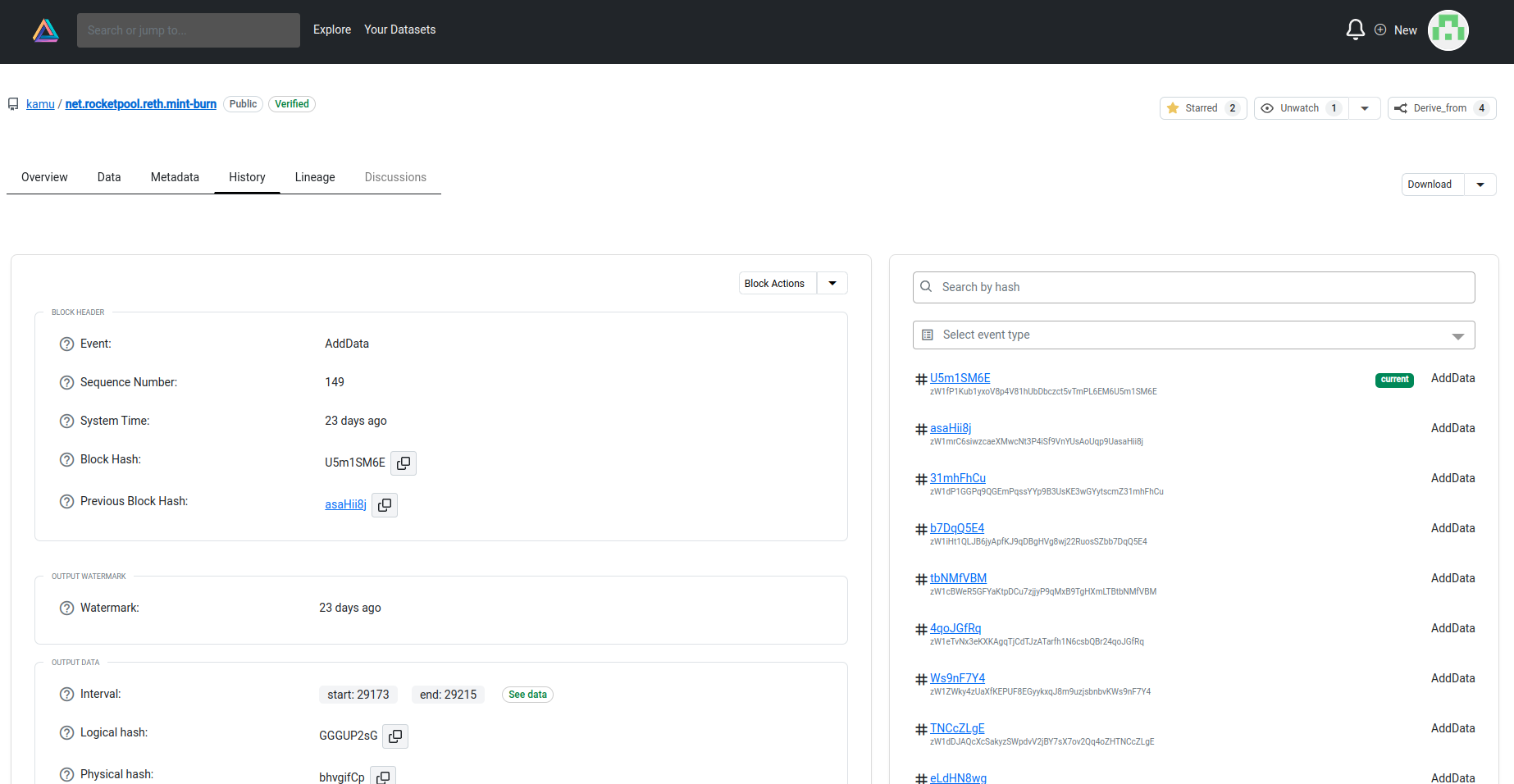
- Etherscan - as a place to inspect the dataset metadata ledgers, see verification attestations, and the state of the network:
- Snowflake - as a place to do ad-hoc exploratory data analysis:
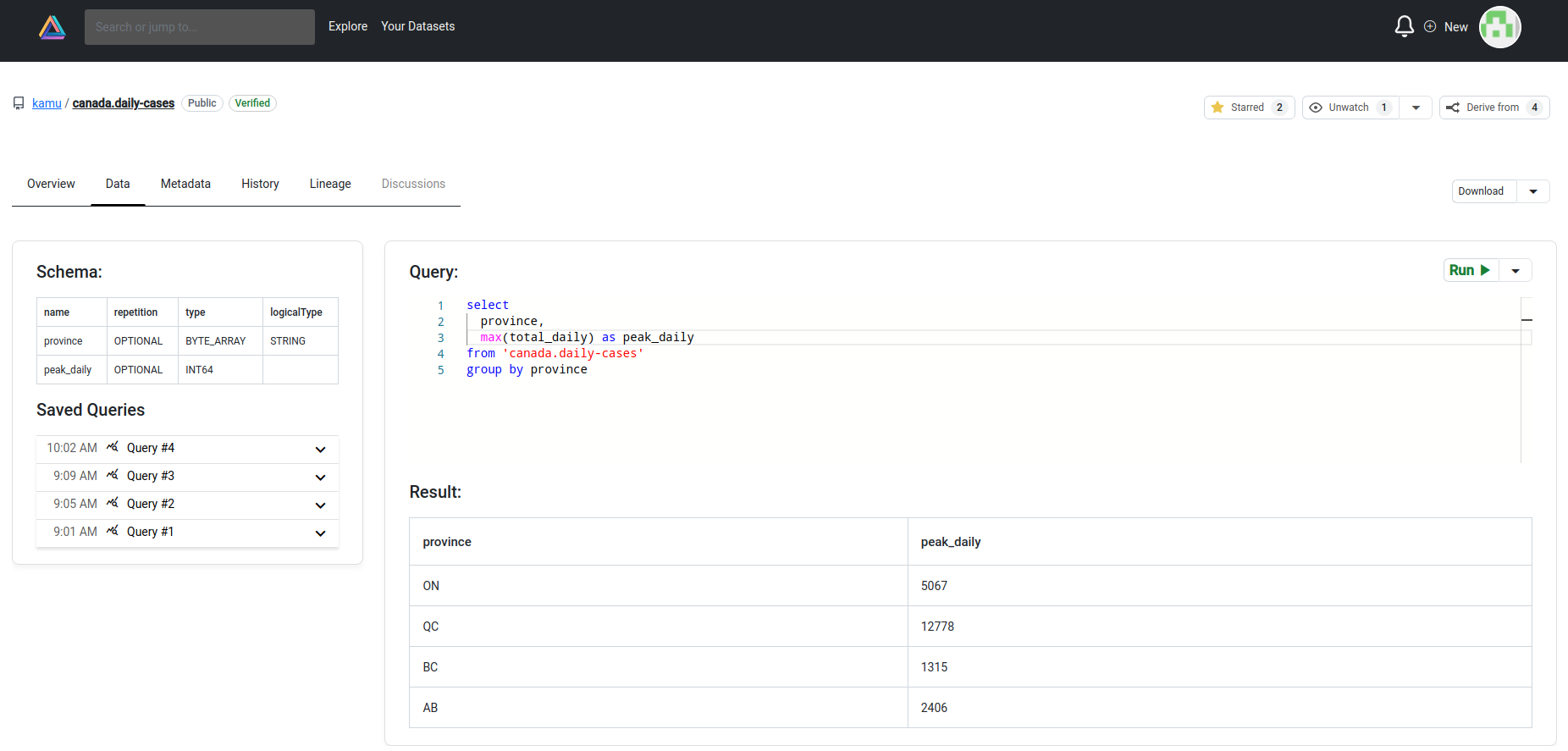
- And Jupyter Notebooks - providing basic analytics/dashboarding functionality
There will be a public instance coming, but you will always be able to run it yourself. It even comes embedded in kamu-cli so you can run it to explore your local workspace:
|
|
Our work so far was focused on:
- Covering most of the read & explore functionality (search, pipeline graph, metadata block explorer)
- Responsive data querying and exploration
- Dataset creation and editing UI, including especially complex pieces of UI for ingesting data from external sources.
Web UI interacts with the Compute Node via GraphQL API which you can also use for all kinds of automation.
New DataFusion Engine #︎
As you may know, Kamu / ODF does not dictate the use of any specific data processing framework or language. Any engine can be integrated as a plug-in. For our initial engines, we chose Spark and Flink as the most mature implementations of the bitemporal stream processing model.
However, these engines were developed with an enterprise setting in mind. They are designed to operate in large long-running clusters, where a startup time of 10-15 seconds and the memory-hungry JVM didn’t matter that much. The quick checkpoint-to-checkpoint nature of processing in kamu-cli goes against this, with 90% of processing time usually spent waiting for engines to boot … it’s a poor user experience.
Recently we have completed a prototype integration of Apache DataFusion engine - a rapidly-developing Rust-based data processing framework built on top of Apache Arrow with a powerful SQL API. While this engine has some limitations it can be many orders of magnitude faster than Spark or Flink in many use cases.
We are very excited about this new generation of data engines. We hope they will pay closer attention to the temporal / streaming data processing paradigm. And as a project that is constantly seeking common ground among the wide variety of implementations, we are strong supporters of Apache Arrow ecosystem and the Substrait project, aiming to unify how we compute on data.
We are already working on replacing Spark with DataFusion in our data ingestion path, so expect kamu to get much faster!
Fast & Efficient Data Transfer #︎
From the very beginning ODF protocol was following a spec-first approach and we remain committed to design and build in the open and seek opportunities for standardization.
As a snippet of this low-level protocol work consider RFC-008: Smart Transfer Protocol. When you think about efficient and standard structured data transfer protocols, what comes to your mind?
- Is it “good” old JDBC/ODBC?
- Or REST+JSON API, which are not standard at all?
- If you are “in the know”, perhaps Arrow Flight?
There is a big gap in these protocols:
Often the server controlling the access to data is not the one storing it. If our Compute Node (server) is deployed in EKS while all data is in S3 (storage) and clients often want to download large datasets - the entire data will have to flow through the server, creating a lot of extra work and a bigger bill.
ODF Smart Transfer Protocol takes care of this problem by allowing to point the client to a piece of data potentially served by a different party over a different protocol, avoiding proxying. In the above case, it will return the client a list of pre-signed S3 URLs to download Parquet files from.
Note: The Delta Sharing protocol by Databricks is the closest thing to this, but unfortunately was too Spark-specific for us to adopt it.
In future, we are planning to extend it to handle in-band data transfer as well, via Arrow Flight protocol, so that depending on the query the system could pick the most efficient way to transfer data to the client.
What’s next? #︎
We will soon be publishing a public roadmap so you could follow both our progress and provide input for future development!
A few upcoming things I’m most excited about are:
- DataFusion-based ingest
- Laying foundation for granular authorization (based on UCAN protocol)
- IPLD migration
- Documentation upgrade.
So stay tuned! You can always find us on Discord as well as many other like-minded people happy to chat about everything data-related.