We have recently delivered two long-anticipated updates that improve performance, broaden engine selection, and let you connect kamu to a wider range of analytics and BI tools.
Let’s dive in!
100x Faster Ingest with DataFusion #︎
When ingesting data info Open Data Fabric’s ledger-like format kamu does a lot of work under the hood. Aside from downloading and parsing data it may need to deduplicate event records or perform Change Data Capture on snapshot data (see Merge Strategies docs for details).
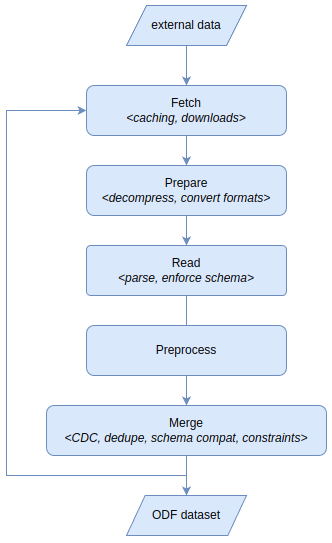
Ingest process stages
Historically kamu relied on Apache Spark engine to perform all this work, but recent releases now also extend support to Apache DataFusion engine.
We previously covered the amazing performance benefits of using DataFusion for derivative transformation, and this update expands them to data ingestion.
It’s an entirely new implementation of data readers and merge strategies that:
- Is often over 100x faster than the Spark-based ingest
- Can work directly over S3 and other remote storages without downloading all data locally
- Supports all existing data formats (Parquet, CSV, NdJson, GeoJson, Shapefile)
- Does not rely on containerization
- Uses far fewer resources, suitable for constrained environments e.g.:
- edge / IoT devices writing data directly in ODF format
- if compiled into WASM,
kamucan bring data-intensive operations to local-first apps running in a browser
Before DataFusion ingest becomes the default option, all you need to do to try it is specify engine: datafusion in your root dataset manifest. All of our examples were already updated accordingly.
Better Connectivity with FlightSQL #︎
Reproducible and verifiable data is an important (but currently non-existent) foundation of any analysis, report, or ML training. The sole focus of kamu is to fill this gap - to be a reliable data supply chain for your projects.
Therefore, we want to make it super easy to consume data directly from kamu in any analytics or BI tool, or AI/ML framework. As the latest step in this strategy we are happy to introduce the support for Apache Arrow Flight SQL protocol.
Data connectivity has been a sad story for the last few decades. The only things we had close to a standard were JDBC and ODBC protocols that were notouriously hard to implement and often inefficient, prompting database vendors to design their own custom protocols. Just look at any BI tool and you will see the effect of this - dozens and dozens of custom adapters for every possible database.
DB driver galore!
Flight SQL protocol addresses this problem as a standard wire protocol for structured data transfer, based on Apache Arrow.
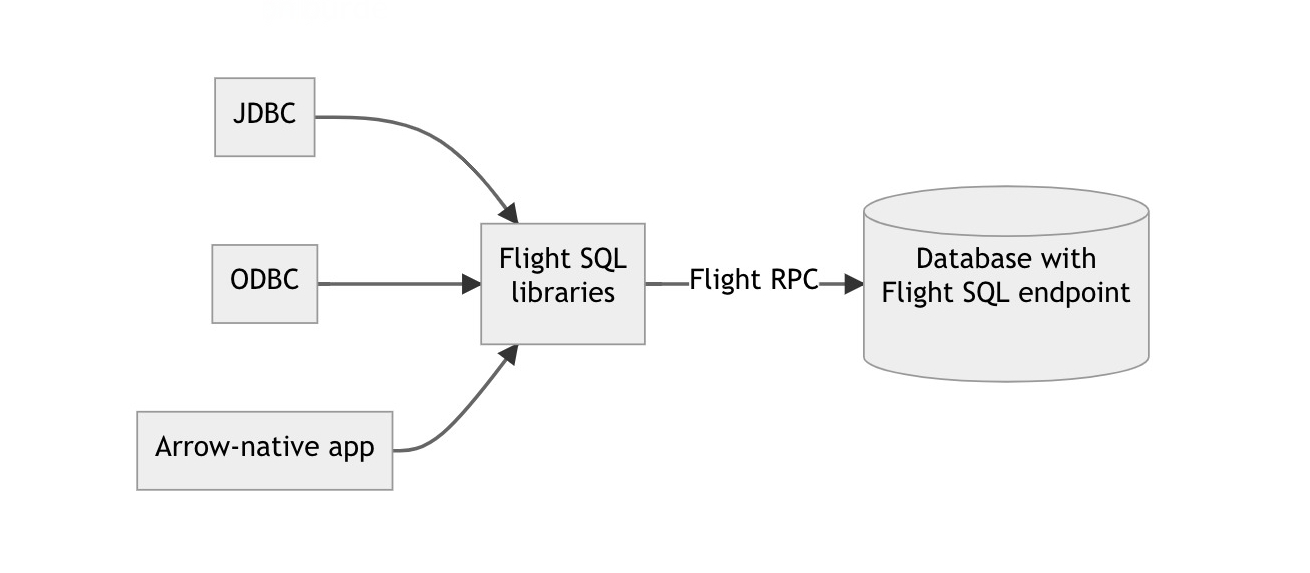
FlightSQL - unified DB access protocol
To find out how it works exactly you can read this official anouncement, but for kamu it offers a well-designed and high-performance starting point from which to expand our connectivity without us spending years to write custom drivers.
The initial Flight SQL integration already allowed us to rapidly expand our connectivity! Below you can see me querying data in kamu directly from Tableau and DBeaver:
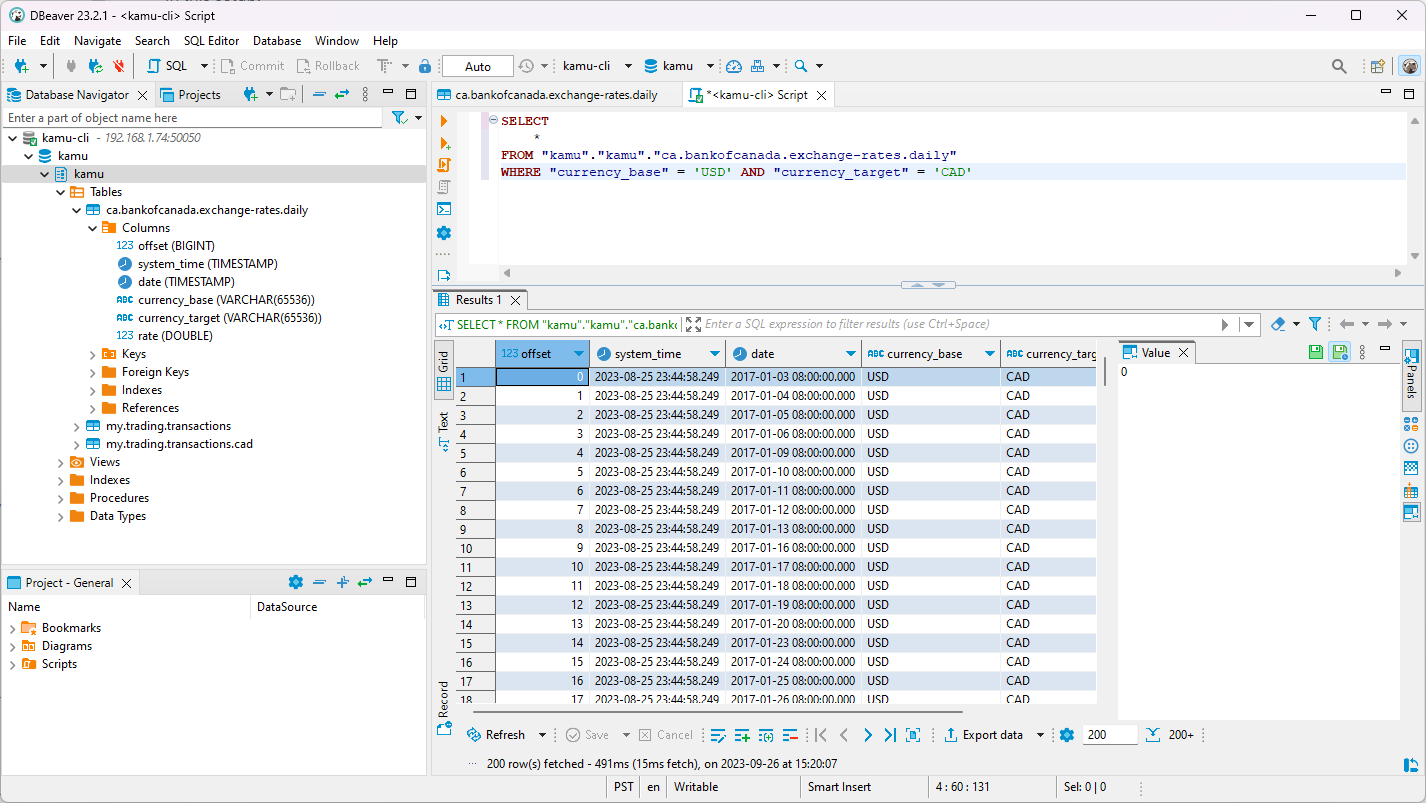
Kamu <> DBeaver
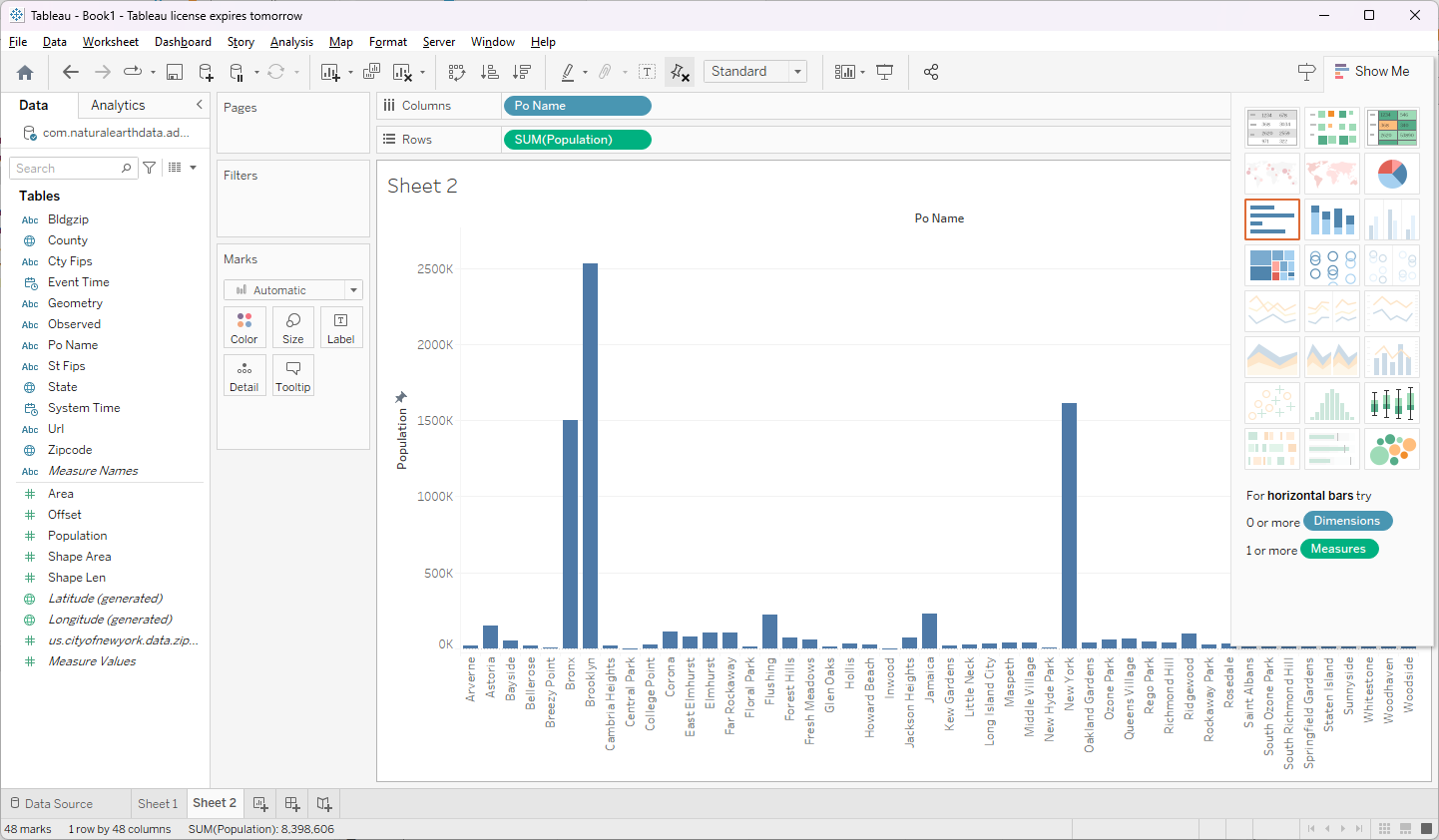
Kamu <> Tableau - basic analytics
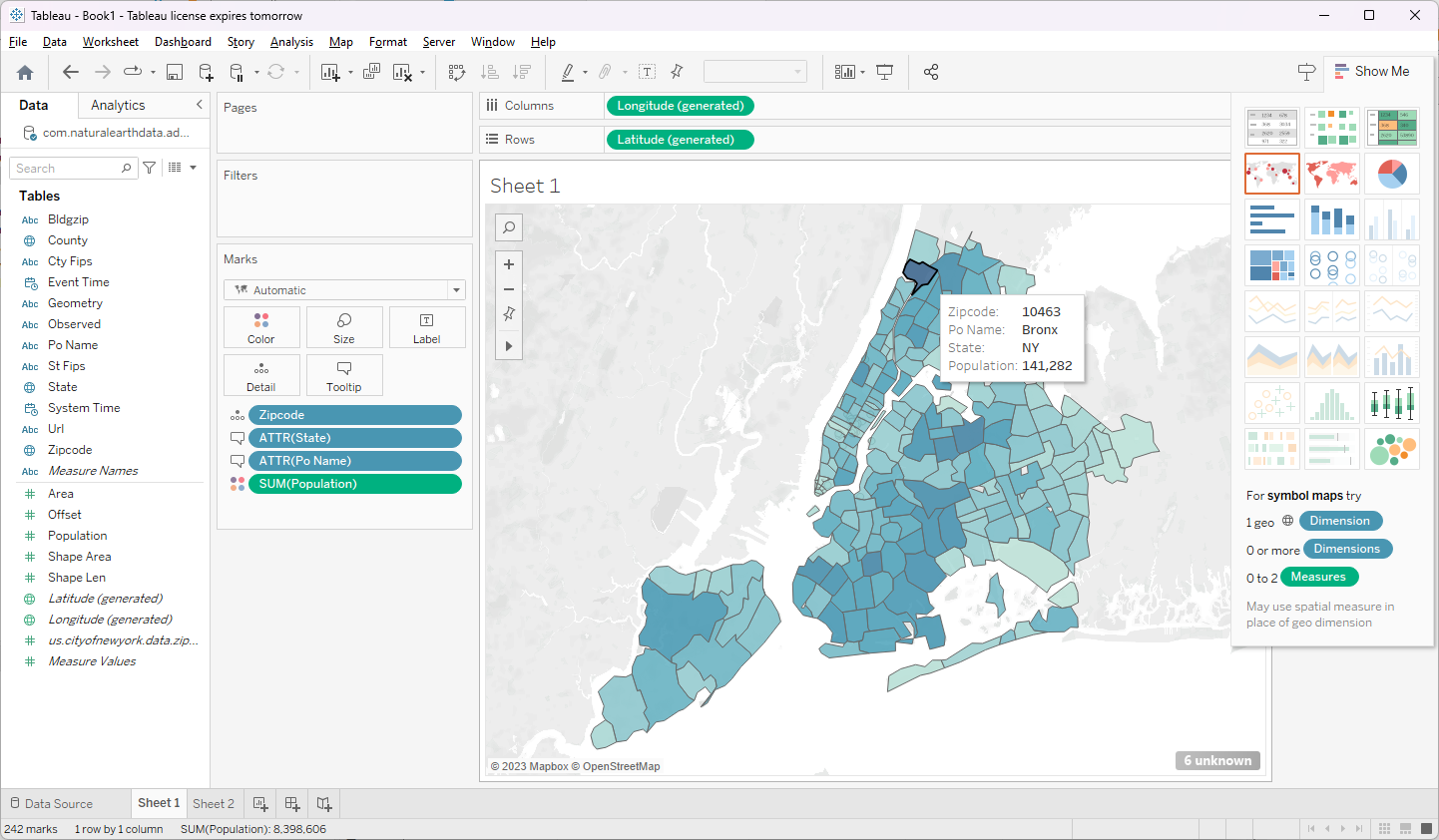
Kamu <> Tableau - GIS data types
Running Flight SQL server is as easy as:
|
|
You can find instructions on how to connect different tools in our docs.
What’s next? #︎
Further development in these areas will include:
- Promiting DataFusion to default ingest engine
- DataFusion-based SQL console
- Integrating faster alternatives for stream processing engines (e.g. Arroyo / Materialize)
- Expanding connectivity to ODBC to support Excel and PowerBI
- Using Arrow-native ADBC protocol based on FlightSQL to gradually replace Spark + Apache Livy combo in Jupyter Notebooks.
That’s all for today! Find us on Discord to stay up-to-date with the development of ODF and Kamu and talk to other like-minded people about everything data-related.