

This post will be very different from the rest - it’s our team’s attempt to explain the state of the data market as we see it and make some predictions.
It’s a long read.
Data market is damn complex, to the point where I think no one has a complete understanding of it including data company founders, gatekeepers of capital, or especially the users. So what makes us qualified to even attempt to touch on this topic?
We believe that a lot of this complexity is incidental, not inherent, and can be untangled. By the nature of what we’re building, we interact with a much wider range of users than most, as we try to bridge data between previously non-overlapping areas like scientific data management, government, healthcare, finance, insurance, civil infrastructure, Web3, telecom, automotive, aerospace, commercial fishing, green energy and ESG, and many more. This gave us a good picture of what solutions everyone is using and what aspects of data management they prioritize. As a highly technical team, we can now quickly put each new solution we encounter into a certain “bucket”. Along the way we also developed some opinions on where all of this is going, that we will share today.
This problem is multi-dimensional and impossible to linearize, so excuse me hopping from one topic to another. Also forgive many generalizations and assertiveness of the tone - it’s for the sake of being concise.
- On Industry Outlook
- On Transition Path
- On Automation
- On Composability
- On Supply and Demand
- On Ownership
- On AI
- On Web3
- On Privacy
- Conclusion
On Industry Outlook #︎
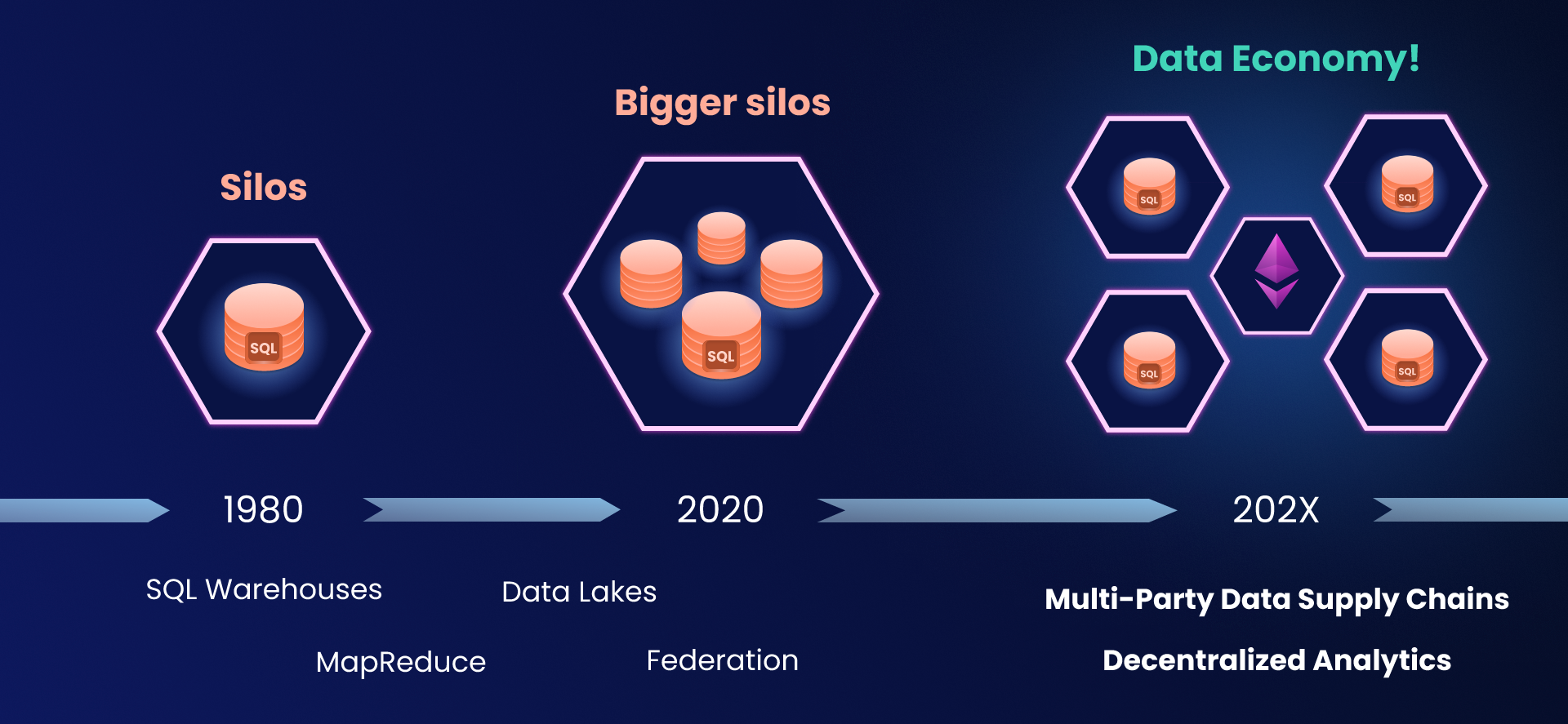
Technological transition to data economy
For the past four decades innovation in data engineering was driven almost exclusively by big tech solving their internal problems using analytics over internal data. A revolutionary invention - relational database - was followed by steady evolution towards larger volumes and lower latencies.
We see this trend continuing in the current generation of startups and emerging tech:
- Startup takes a popular data solution X
- Builds a faster version of X
- Open-sources the core
- Sells the cloud version
We believe this model will have steeply diminishing returns:
- As performance gains stemming largely from Apache Arrow and moving away from the legacy JVM stack are incorporated into all major data engines, and as open-source data formats like Iceberg gain wide adoption - this leaves very little room for differentiation. There is surely enough market for competition - lots of big companies are still transitioning away from the outdated warehouses and you can “catch” them at the right moment - but this will increasingly be a sales race, not a technological one.
- The current processing model is reaching its limits - not in performance, but in human cost of operating it, how manual and fragile it is. Its flaws cannot be patched and will require a major re-design of engines, disrupting the established order in the analytics market.
- An organization can only derive limited value from internal data, whereas external data holds immense untapped potential. Using internal data organizations can optimize their processes and efficiencies, but only using external data can they act strategically - access customer insights, compare their performance against peers, and better understand their place in the global market. [sloan] [deloitte] [forbes]
Organizations exchanging information with one-another will become the main focus of the next decade in virtually every sector of the economy and we’ll show that the current solutions simply aren’t designed with this in mind.
Today we barely scratch the surface of strategic use of data - the next decade will be the time of transition from internal silos towards the global data economy.
Aside: Don’t we have a data economy already? #︎
Emailing Excel files and PDF reports still remains the primary way of data exchange - a highly manual and error prone process that we often compare to the Rube Goldberg machine. In data startup circles this is considered a “low-tech” segment and not the area to focus on, but we believe that this is a clear indication of a big gap in solutions and a big part of the systemic problem.
Companies that already operate data lakes are not much better off. They often drown in internal data, unable to tell where most data came from and how it was processed. While solving storage and querying, data lakes are low-level tools that don’t provide good mechanisms to manage data workflows, thus even internal data exchange always ends up plagued with provenance and quality problems. When companies need to share data with partners, they often resort to highly custom solutions tailored to each consumer, which are costly to develop, maintain. Lack of good privacy frameworks often leads to multiple copies of data at different levels of detail being produced that add to confusion and erode the “source of truth”.
Lack of interoperable solutions is most noticeable in the scientific and government data space where universities and governments have policies to publish data, but keep developing custom non-interoperable portals. The amount of redundant effort is in tens of billions and data remains hard to access. They do this not because they don’t have money to pay for Databricks or Snowflake - govtech solutions are extremely overpriced - they do so because their requirements around data sovereignty are not met.
REST APIs remain the most widespread way to monetize data, but we think this model is flawed:
- APIs are the means of delivering data to applications, they are not fit for data science and analytics.
- They are non-standard and always require custom integrations
- If the focus of your company is not on selling data - building data API infrastructure is too significant of an investment. Many companies in automotive, telecom, and other spaces that have very valuable data, but told us they can’t monetize it because of the costs to build and maintain such infrastructure.
- APIs thus favor big players, lead to centralization, and produce data monopolies. It’s not possible for a few small publishers to “pool” data together - APIs don’t compose.
When it comes to publisher-supplier relationships, all companies still operate through bilateral agreements. A health insurer will contract an actuary that in turn has deals with dozens of hospitals to periodically get statistical data. Again, the entry barrier into this system is very high, getting data takes a lot of time, and due to how manual the whole process is - you will likely be seeing data that is long outdated and can be barely trusted. The only thing that tells you that the data you get from an actuary is real is an ephemeral feeling that “they do data as a company, so it must be real”.
So, no - we don’t see the current state representative of even a small fraction of what the global data economy will look like.
On Transition Path #︎
There of course have been hundreds of attempts to enable data economy by building “global data portals”, and “data marketplaces”, but all of them turned into data graveyards. There has been a resurgence of data marketplace attempts in Web3, but they all focus on using blockchains to experiment with different economic incentive models, leaving data engineering foundation the same. The continuing attempts are evidence that the problem is worth solving, but making actual progress will require substantially rethinking the approach.
We don’t see this transition happening gradually as an evolution of existing practices. Cross-org information exchange is a trustless environment, very different from mostly-aligned incentives within a company - existing solutions were not built with any of these requirements in mind and they are impossible to retrofit. The current solutions for managing the internal data already require organizations to have large engineering teams to sustain - we cannot expect them to also handle the external sharing side. We’ve hit the complexity limit - this won’t scale.
The current state is a local optima and getting out of it is not going to be easy.
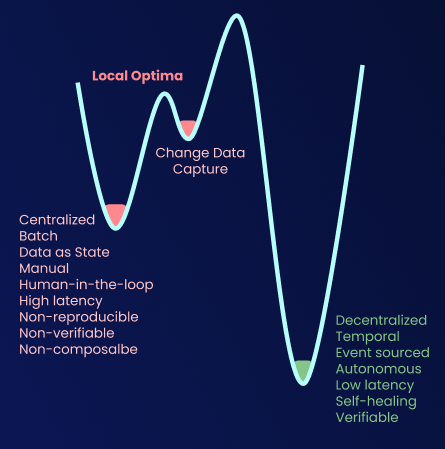
Local optima
The set of problems that must be solved during this transition are:
- Automation
- Composability
- Trust & Accountability
- Ownership
- Decentralization & Interoperability
- Privacy
While many VCs are looking for “The Next Snowflake / Databricks” - we don’t think this is what a solution will look like. The gap is certainly wide enough for another behemoth, but thankfully the market will not tolerate a centralized / proprietary solution to this problem. A solution will likely have the form of open formats, a specification that multiple different data engines can adhere to, and a “Fat Protocol” that serves as an interoperability layer for various on-prem-first implementations that respect data sovereignty, unlike the current cloud data platforms. We of course hope that our Open Data Fabric initiative can fulfill this delicate role.
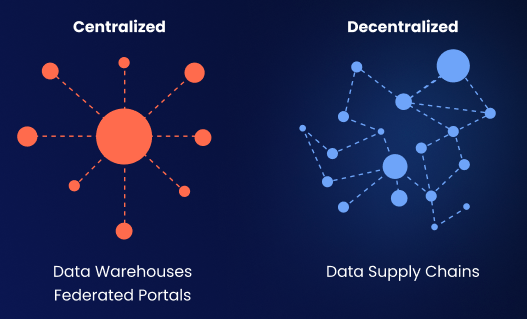
Data lakes vs. supply chains
On Automation #︎
When I say “real-time data” what’s the first thing that comes to your mind? For most, it’s probably the stock market with its high-frequency tickers.
We ask: Why isn’t all data like that? Why do events like the release of quarterly employment reports in the US still cause market swings as traders try to predict what these numbers will look like? Why can’t we get those numbers on an hourly basis?
The answer is - because of the current data processing model that is extremely manual, fragile, and keeps humans in the loop.
To emphasize, even if all data in the world by some miracle was in a single well-structured, perfectly-permissioned database - we don’t think the situation would get significantly better - the current model is unfit for automation at scale.
In our The End of Batch Era blog post we attribute this problem to batch processing - a computational model that constitutes >99% data processing today. This model doesn’t know how to work with time - the most fundamental dimension of data. With industrial-IoT growing massively, blockchains becoming significant and high-frequency data sources, and all sorts of dynamic consumers like devices, automation, and AI bots in play - we need a better computational framework.
This framework already exists - Stream / Temporal Processing (we prefer the term Temporal Processing to break away from the old solutions that were just working with time-series data and message queues like Kafka that for many people are synonymous with streaming). It is already revolutionizing how big tech works with real-time data, but we think enterprise data companies are again largely missing the point. Yes, it improves latency, but this is actually one of its least fascinating properties.
More importantly:
- It provides a solution for dealing with data incompleteness
- It allows to write code that processes data continuously while it evolves over time, automatically reacting to backfills, retractions, and corrections
- It removes humans from the loop - people design and build pipelines, but don’t move any data manually. Removed from the “hot path” of data they don’t contribute their oh-so-human latency and mistakes to it
- It composes - pipelines can have thousands of steps that are reactive, self-healing, and autonomous.
The importance of stream processing technology is comparable to the invention of calculus - it’s a new framework for problems for which previous methods were not a good fit.
If a new data solution does not consider temporality - I usually stop looking.
On Composability #︎
Let’s say with a swing of a magic wand we move millions of existing data publishers and consumers to one platform. This utopia can easily backfire and turn into a systematization nightmare. We immediately run into M*N quadratic complexity problem where all data is hard to discover, takes a lot of effort to combine together, is riddled with quality and trust problems, and every consumer has to deal with these issues themselves. These are the same issues as a poorly executed transition to data lake leads to, but now on a global scale.
Once again - removing interoperability barriers alone is not enough.
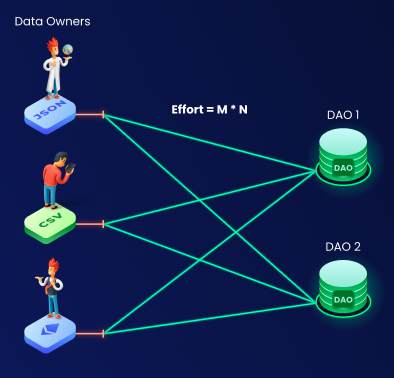
Complexity explosion in a non-composable model
For the data economy to function we should stop thinking about data as fruits on a stand that change hands, or as parcels sent through a logistics network. Instead we should think about data as plumbing or an electrical grid - a highly-interconnected network of supply chains that flow, diverge, and converge continuously and autonomously. These chains form a DAG, and graphs provide structure and hierarchy.
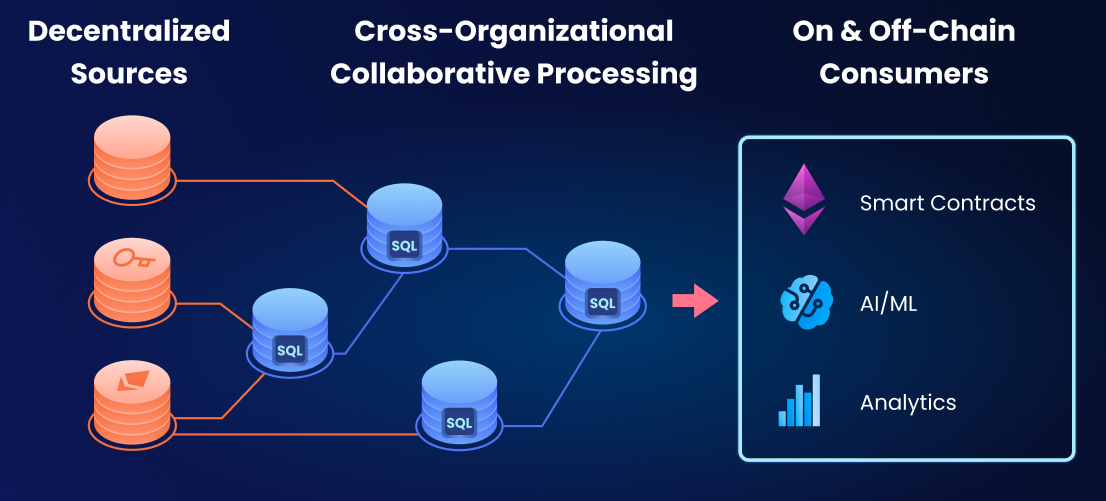
DAG of streaming data pipelines
This is where composability on processing level that we just touched on turns into composability on a global cross-organizational scale:
- Data from publishers is flowing
- It’s picked up by the global community of data scientists and that combine, aggregate, and extract value from it
- Consumers access data on various levels of aggregation
- Any retractions or corrections propagate instantly to consumers
Data composition is the only way to solve systematization and quality problems at global scale, yet all mainstream data solutions don’t offer a composable model.
On Supply and Demand #︎
Data economy needs a balanced supply and demand. Demand is already high and will only get higher once data access barriers drop. Supply however is critically low. The current technologies created a steep entry barrier and failed to create the right incentives for publishers to share data.
We must recognize that for most companies publishing data will never be the core part of their business - a supplementary income at best. Publishers therefore should be treated as the most fragile and vulnerable persona in the model as any extra effort needed on their end significantly reduces chances of getting the data.
That’s why we believe that a much more opinionated and simpler to use data solution is necessary to fill the gap between Excel and a data lake in these lower-tech companies. Publishing data externally must be a natural extension of internal data workflows otherwise operating overhead will be hard to justify.
Also that’s why we pay close attention to the government use cases (another underserved area), as regulatory requirements may just be the driving force that makes such companies upgrade their data stack to keep up. Privacy-preserving verifiable analytics is essential to make regulations and compliance sustainable without falling into the extremes of a “surveillance state” or a 3rd party audit mess.
There is also what we call a “small publisher dilemma”. The smaller the publisher - the less data they have, the harder it is to find, the more work for a consumer it is to integrate, and therefore the less valuable it is. So, for example, while data from all taxi companies in the world would be immensely valuable - data of one taxi company may not have any demand, and thus discouraging a company from ever trying to publish.
The NY Taxis dataset was a clear illustration of how fast things can go once you overcome the initial friction. When the New York government collected and shared this previously inaccessible data it turned out immensely valuable and has since spread to dozens of data portals, was featured in hundreds of conference talks, and benefited many ride sharing startups.

One of many NY Taxis dataset visualizations (by Ravi Shekhar)
Again, we believe that composability is the solution:
- Publishers only need to expose data in its raw form
- Data scientists can then find publishers within common domain, clean their data up, harmonize and pool it into higher-order datasets
- The data is then provided wholesale to the consumers
- Pipelines keep running autonomously as long as publishers continue to provide data
- Rewards flow upstream and are shared between publishers and the pipeline maintainers.
Composability here plays a crucial role of allowing parties other than the publishers to perform most of the heavy-lifting, dramatically reducing the barrier of entry.
Today there are many companies that specialize in sourcing data and data cleaning. By making data composable, this role can be opened up to a global community of hobbyists and researchers, replacing actuaries with transparent, auditable, and verifiable pipelines.
We see composability foundational to collectively-owned data supply chains, governance of which can be automated through smart contracts (aka Data DAOs) to avoid the complexity of custom data redistribution and revenue sharing agreements and further simplify publisher participation.
On Ownership #︎
Taking composability a step further in another direction naturally brings us to personal data ownership. In a truly composable system raw data can be collected on device / individual level and then be progressively combined into higher-order datasets. For example, data of a commercial fishing company may be a union of datasets of every ship they hire, while the ship’s data is a union of datasets of individual IoT devices on board. As devices are installed, break, get replaced changing vendors - a digital twin of a ship can be seen as an ever-evolving (temporal) graph of streaming pipelines.
Note how this approach is bottom-up - a device is installed and starts writing data to its own dataset, and then this data is incorporated into the supply chains feeding the ship’s digital twin and company analytics. Many digital twin solution use a top-down approach where a common data schema is designed first and then devices are made to write to it in a specified format. Designing such a common data schema is a tough social exercise of seeking some common denominator and consensus between many device manufacturers - good luck attempting this on a global scale.
In a bottom-up approach:
- Data can start flowing immediately
- Be quickly aggregated in a way that suits internal needs of a company
- And later harmonized for consumption on country / global level
- Even if the internal model of a company ends up incompatible with what the rest of the market settled on - a company can easily create and migrate to a new model as all raw data on device level is still preserved.
The permissions in this model work very naturally as well - they can be enforced on per-device level, the control can be delegated to captains, who authorize access by fisheries. When the ship’s contract ends with one company - the read permission for future data can be revoked - leaving the company only with access to data that was gathered while the contract was active. Complete data stays available to captains to base maintenance on, and may or may not be available to the next company that contracts them (e.g. a ZK proof of sufficient maintenance may be all they get).
Individually-owned data will make up the “big data” of global analytics while preserving the IP ownership, enforcing the desired degree of privacy, and maintaining provenance links for equitable reward distribution.
On AI #︎
No matter how sophisticated your AI model is, if you train it with poor data you will get poor results: garbage in, garbage out. Acquiring and preparing data is absurdly hard - AI startups spend >80% of time gathering data instead of designing and tweaking models.
AI is a data problem.
Our theory is that the boom of LLMs is a side-effect of the data problem - it’s a lot easier to build an AI startup that scrapes open information from the web than to go through all the hurdles of getting specialized domain data. Companies that crowd-source data generation, like Shutterstock and Getty are making $100M annually from AI companies. Meanwhile domain-specific AI stagnates, facing privacy barriers, complexity of bilateral data acquisition agreements, and custom integrations.
It’s not the algorithms that make a successful AI company - it’s the strategies and business relationships behind data acquisition.
If these barriers are lifted we will see a boom of domain-specific AI applications.
LLMs continue to improve rapidly, but also are rapidly commoditized. Many open-source LLM models now exist as alternatives to GPT. Companies training the foundational LLM models are publishing information about their algorithms, but none so far shared the details of their data sourcing and preparation pipelines. Same goes for applied LLM startups - none of them seem to have a strong defensibility moat other than where they get and how they prepare data for fine-tuning. Their early gains will likely be quickly eaten away by the competition and the value will move upstream towards data.
When dealing with hype technologies it’s better to pay attention to the fundamental infrastructure that supports them. This was the case with semiconductors that surged first due to Blockchain mining and then AI booms - NVIDIA is the most valuable company in the world as of this writing - same will be the case with data infrastructure. Unlike algorithms and models though, data has inherent and profound network effect - data is a lot more valuable when highly interconnected and can be easily combined with other data. A protocol that solves data exchange problems will have a significant moat due to this built-in network effect.
In Kamu we see the relationship between LLMs and data changing significantly. LLMs are notoriously bad at factual information - they have no defined boundary between facts and “dreaming”. The models are already huge, so it’s simply impractical to try to embed more factual data into them. Even if the size is not a concern - in the constantly changing world a lot of data will already be out-of-date by the time you finish re-training the model. We therefore think that LLMs should be treated as a human interface that can help people access and make sense of factual data, but not necessarily contain it within itself.
A simple example of what we’re prototyping:
- LLM receives a question like “what is the median price of a 2BR apartment in Vancouver?”
- Using semantic graph of datasets in Kamu (via RAG) it finds datasets that are most suitable to answer this question
- It composes an SQL query to fetch the data
- And determines the best representation (verbal, or graphical) to serve the results.
The symbiosis of LLMs and a data supply network can deliver users factual real-time results, without having to frequently re-train the model.
Perhaps even more importantly, it can deliver the results with full provenance information, and therefore enable both accountability and fair compensation of data providers. When this state of technology is achieved we see AI becoming possibly the largest consumer and the primary user interface for data.
The Scarlett Johansson lawsuit against OpenAI once again turned the attention towards provenance of data used for training and compensating the IP owners. We think this is the wrong side to start digging from. You can already establish a link between the AI model and data used for training - currently through versioning / anchoring data and deterministic / verifiable computations. But we also need to establish provenance across all the hundreds of transformation steps data usually goes through before training, linking it to ultimate roots of trust - the individual data publishers. Training an AI model is not that fundamentally different from executing an aggregate function in SQL, thus if we solve provenance at a level of multi-stage data supply chains - AI training will fit into the general framework nicely. And if your data ownership extends to individual level (as we described in Ownership section) - you’ll have a programmatic way to compensate the IP owners. Try starting with the training provenance problem and you’ll end up linking models to data the origin of which cannot be established.
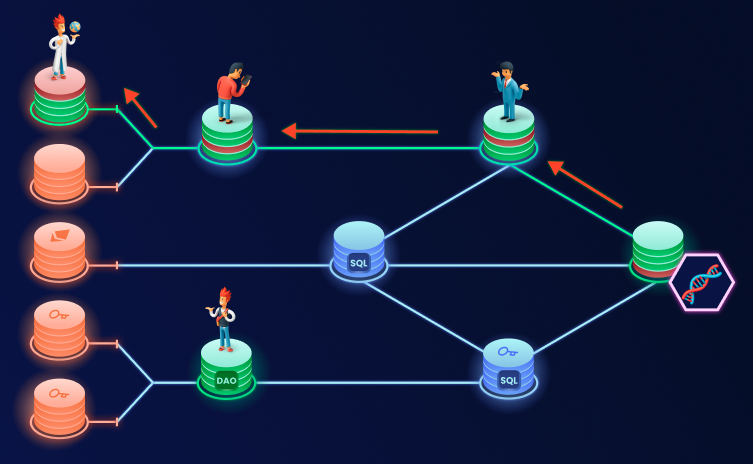
Using data provenance to reward IP owners
And finally, today AI/ML is primarily the end product of data processing - you collect and shape data, train a model, then deploy it to serve users. We think this will change as well. Once we can produce verifiable models with strong provenance we will see more of them being used as intermediate stages in data processing pipelines. We are building Kamu to make AI-enabled classification, feature extraction, alerting, and all kinds of decision making a seamless part of the data supply chains, as simple as running an SQL function.
On Web3 #︎
We already stated that the market will (rightfully) resist any centralized / proprietary solution to data exchange. For most organizations NO data exchange is better than having their data held hostage. This naturally brings us to Web3 and the realm of decentralized protocols.
Blockchain investors themselves describe this market as “self-serving” and in the state of a “big casino”. There’s definitely a lot of that. Despite that, Web3 operates much closer to the underlying challenges of multi-party trustless information exchange and already gave birth to several extremely important new technologies like decentralized storage and compute networks, and novel privacy-preserving techniques.
When it comes to data, the biggest issue we see is Web3 companies building solutions for other Web3 companies in isolation, disregarding the transition path for the other 99.9% of the organizations in the world. If a company already operates a data lake based on S3 - why on earth would they want to move their terabytes of data to some decentralized database and lose access to Spark and other vast sets of analytical and BI tools that they built their business around? Our theory is that the current state of affairs is caused by the profile of engineers - most people that come to Web3 today were only exposed to OLTP (transactional) data processing before and create data solutions that unfortunately repeat the same mistakes that OLAP (analytical / warehousing) data processing already evolved out of decades before.
In Kamu we take a very sober, practical look at Web3 and build towards its core values, but with existing enterprise OLAP data users as the starting point. Web3 values are the “north star”, but we need to make sure that the on-ramp is as smooth as possible. With our products, we have already proven that provenance and verifiability can be introduced into modern data lakes in-place, with little to no disruption. Users can continue using their existing storage, their existing tools, and open their data to others and decentralize progressively, when there is a strong business case to do so.
As a quick rundown of technologies:
Blockchains: We see them as OLTP engines for multi-party interactions. Most data is not that. Putting data on blockchain is prohibitively expensive, so this discourages the abuse of blockchains for data storage, although many startups still try. Private / enterprise blockchains are just stopgaps for privacy and scaling issues - we don’t consider them as good mediums for data exchange either, as none of them can handle Industrial-IoT volumes and frequencies of data. We use blockchains as censorship-resistant data catalog, permission management layer, and as a source/consumer of some data (see below), while keeping all data processing off-chain. Data doesn’t need a global ledger. Verifiability of data pipelines has much more efficient solutions than what general purpose blockchains offer.
Oracles: Access to trustworthy off-chain data is essential to make Smart Contracts useful, but The Oracle Problem remains a big barrier. We strongly believe that the oracle problem is a feature, not a bug. The issue of how holding data providers accountable exists even when you call Google’s REST API from your app – today you have no way of proving that resulting data even came from Google, not to mention disputing it. The oracle problem simply exposed the lack of accountability in modern data exchange in stark contrast with the properties achieved and held sacred by blockchains. Complexity and cost of Oracle Networks is a big factor in the stagnation of the smart contract ecosystem. If the accountability problem is addressed at the core - bridging data to smart contracts will become trivial, opening up millions of new use cases for smart contracts other than just finance. See this talk about how Kamu is achieving this.
Indexers: OLTP transactions on the blockchains generate a lot of interesting data. The desire to use it for analytics gave birth to the category of solutions that ingest decoded blockchain data into databases and lakes. They all end up re-centralizing the data and going back to all the trust concerns blockchains are solving. Situation is improving with some indexers using Zk-proofs to make some claims verifiable, but this is still very far from general-purpose analytics. More importantly, all indexers provide access to only blockchain data, meaning that if you need to correlate some on-chain data with events happening in the outside world - you are suddenly thrown into complexity of building and operating your own data infrastructure - an investment few can afford. In this talk we show how Kamu unifies oracles, indexers, off- and on-chain data under one simple model.
DePIN (decentralized physical infrastructure networks): Some DePINs like weather station networks exist to gather data. For others data is a byproduct crucial for provisioning, monitoring, and service level control. From the perspective of data, the only difference between DePIN and industrial IoT is in where you draw the ownership boundary. While blockchains are used as an incentive layer for these networks, the massive volumes of high-frequency data will have to go somewhere off-chain while preserving verifiability.
On Privacy #︎
Most companies still consider data privacy only in the form of private networks and centralized permission control. In many cases this may be actually enough for them. Many Web3 ideals like using public storage networks where data is openly accessible but protected by encryption are viewed as additional complexity and often a showstopper. Again, we need a smooth on-ramp - industry must accept that it will take time for these approaches to earn customers’ trust - we should meet users where they are.
Only when encountering cross-org data exchange companies start looking at the domain of structured transparency of which previous approach is just a tiny subset. The most popular solutions there still remain Compute-to-Data and Federated Learning - simple ideas of performing computations within data owner’s infrastructure, without ever sending raw data outside the private network. While posed as the holy grail of medical AI, we still have not seen a single sustainable integration. These solution require not only advanced infrastructure, but a significant technical expertise on the data owner’s side. It’s still hard for me to imagine hospitals en-large ever employing people capable of reviewing the submitted code and AI training routines for PII leaks.
Luckily this field is booming with new techniques that can make structured transparency easier to operate:
- Differential Privacy can control how much information is revealed in aggregate throughout the computation and automatically terminate it when it exceeds some threshold without any human input
- Software Enclaves and Homomorphic Encryption can allow 3rd parties to operate the compute infrastructure without leaking any information to them
- Arguments, Proofs, and Zero-Knowledge enable verifiable and privacy-preserving computing without the need for specialized hardware and the “root of trust”.
We are accumulating a robust set of privacy tools, but the main problem now is that there is no common foundation to integrate them through. When two or three parties are involved in a computation, the likelihood of them using the same tech stack is slim, and we are extremely far from having any standard spec to make verifiable computing interoperable. Until this changes - we will see structured transparency deployed very haphazardly, as custom solutions with hefty price tags, and being close to impractical in terms of cognitive overhead for the operators.
Privacy has to be layered over the open data supply chain protocols. Going the other way around will only fragment the already highly fragmented market.
Conclusion #︎
Every sci-fi movie already captured the desired UX:
- Instant, uniform access to millions of data sources
- Feeds of relevant data delivered in real-time
- Ability to drill down to individual data points and cross-verify veracity of data between sources.
Let’s figure out how to make this vision a reality.
We believe that in Kamu we largely cracked the problem of how the foundation of this should look like:
- Separation of data ownership from storage and compute infrastructure
- Composability of stream / temporal processing as the key to automation, ownership, and global collaboration on data effects of which will likely be similar if not greater to Open Source Software revolution
- Ecosystem based on open formats and protocols, open to many engines and alternative node implementations
- Network economy that fairly compensates all participants of supply chains to keep things sustainable.
Unfortunately this foundation is not a gradual evolution of existing frameworks - a lot of things will need to be re-designed.
Surprisingly, for such a complex problem we have not yet encountered many “forks” on the path to the solution. We have been following the same vision for over 3 years and watching the many puzzle pieces we have not even considered (e.g. the oracle problem) fall neatly into their places.
Do you agree with the trends and problems we described? Reach out to us on Discord with your thoughts and comments.
Try our demo to see a lot of this new foundation already functioning.
If you’d like to know more technical details of what major drivers influenced the technical design of Kamu – subscribe to our news not to miss our upcoming blog post: “The Grand Convergence: Five silent revolutions that shape the future of data”.


