

Hey, it’s been a while since our last update.
We accumulated tons of exciting news, so let’s dig in!
But first, what is Kamu? #︎
What’s the first thing that comes to your mind when I say “data”?
If it’s Excel spreadsheets - then imagine one that keeps real-time record of events that happens in your business, and like an accounting ledger allows you to “time-travel” to see how your data looked like at any specific point in time.
If it’s thousands of CSV files - then imagine a data format allows you to represent highly dynamic data (e.g. IoT), is strictly typed, 1000x more compact, can be efficiently queried like a database, yet remains easy to share and copy between systems, and embeds cryptographic proofs of who owns and who modified each dataset.
If it’s Jupyter notebooks - then imagine a special notebook with code that cleans, harmonizes, and combines data from several different dynamic sources. You can share this notebook with other people, thus providing them with both a stream of continuously refined data AND an explanation of where this data comes from.
If it’s an enterprise data lakehouse - then imagine a peer-to-peer network connecting lakehouses in multiple companies, allowing them to share data with subsidiaries and partners from a “single source of truth” with flexible privacy controls, and build verifiable ETL pipelines that span across company boundaries.
Kamu is a novel data supply chain technology focused on how data travels across organization boundaries. It aims to unlock collaboration on data similar to Open Source Software revolution and build a collaborative data economy based on privacy, clear ownership, and verifiable trust.
The technology itself is pretty simple. Explaining it still requires many analogies only because something like that did not exist before (see step by step technical introduction).
New Partners and Exciting Use Cases #︎
We’ve seen way too many companies (especially in Web3) who spend years developing complex technologies only to realize there is no market for them.
In Kamu we believe that a healthy tech company should minimize the time between developing a feature and putting it to good use in production.
In the face of limited resources and a small team, the best way to do it is to build meaningful partnerships with visionary companies, solve their immediate needs, and grow together towards larger common goals.
I’m happy to announce our continued collaboration with Molecule in scientific data sharing (see DeSci Berlin talk).
🧬 100+ Biotech startups are trusting Kamu with their research data!
We have collaborated with several startups in Decentralized AI space:
- To connect LLM agents to real-time analytical data (see OAG demo)
- To provide provenance trail for GenAI artifacts for copyright and IP infringement protection
- To power tokenomics models that reward data owners and model authors for GenAI artifacts
We are also starting to collaborate with several DePIN companies to unlock private data ownership and democratize DePIN data pipelines, and Industrial IoT companies that need to disseminate high-frequency sensor data.
R&D #︎
These collaborations have pushed us hard in terms of features needed from Kamu Node. Nearly all our efforts this year went into turning the technological foundation we created with Kamu CLI into a scalable back-end solution.
Flow System #︎
Just like how GithHub hosts millions of repositories and runs their CI actions, our public node is intended to host millions of datasets and ingest, process, and validate their data.
Given that pipelines need different engines (Flink, Spark, Datafusion etc.) and different versions of those engines to execute, and we don’t have infinite hardware to keep them running all the time - we need a smart way to schedule these computations.
Enter the Flow System. Flow system is the heart of Kamu Node that beats to drive computations forward.
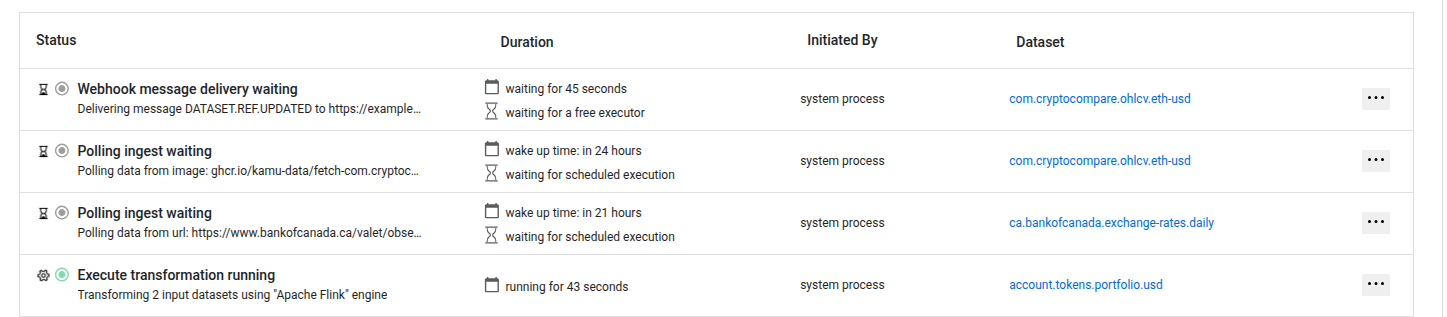
Computations can be of many types, like polling ingestion, derivative transformations, verification, compactions. Flow System intelligently schedules and prioritizes them and spawns execution tasks that are processed according to available capacity.
We decided that the most important thing in the design of this system was explainability - understanding why some actions happened when they did, and what actions will happen soon.
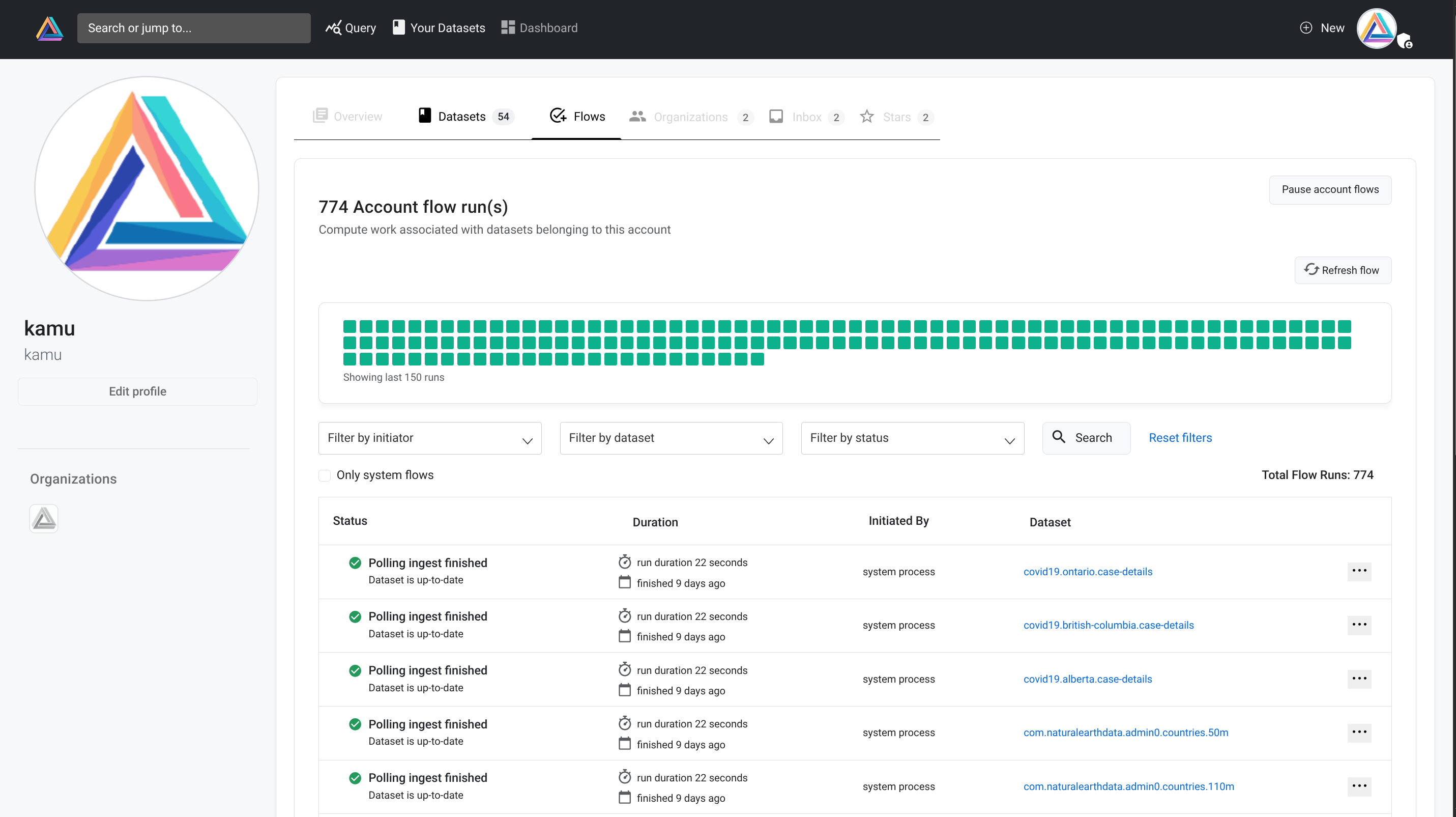
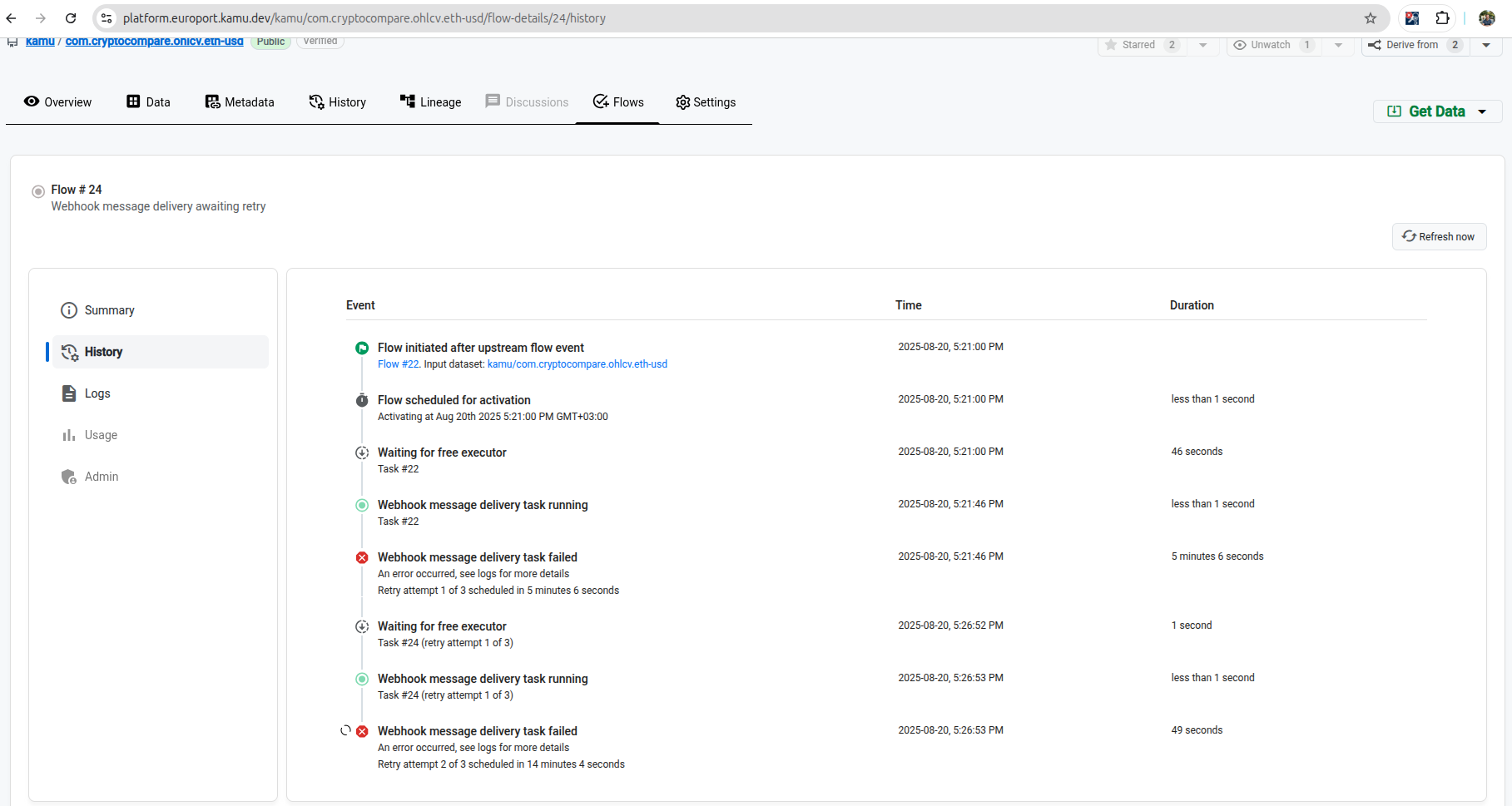
Happy to say that flows in Kamu offer the best explainability I’ve seen in any jobs scheduler:
- You can see the upcoming flows that and estimated time when they will start executing
- You can understand what events triggered a flow and reconstruct the graph of updates
- You can see all queues, batching, and scheduling decisions that were made prior to task execution
We are working to make flows easy to monitor, so you could keep your complex ETL pipelines in a working order.
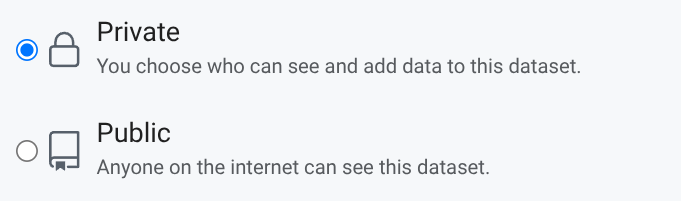
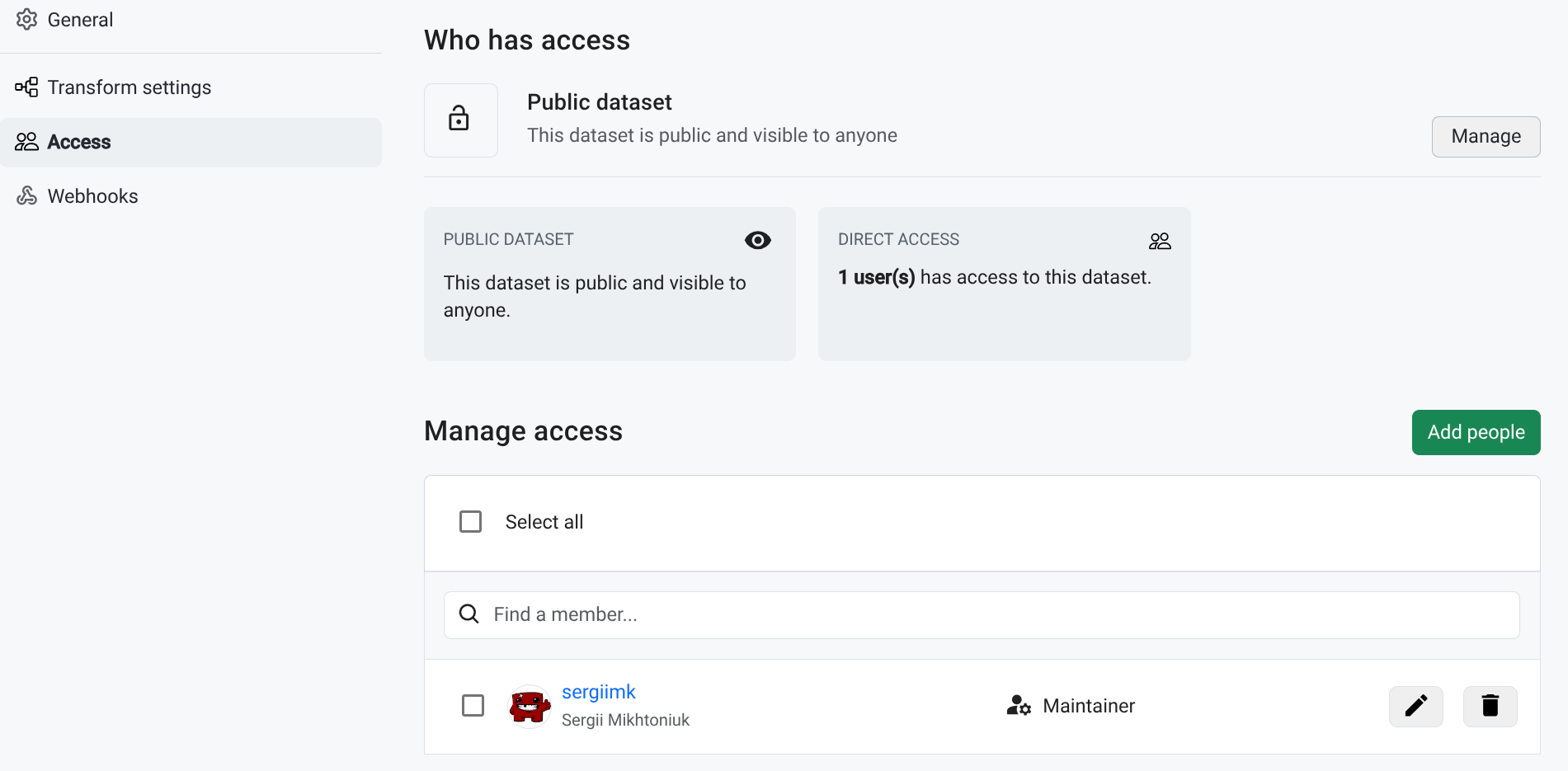
Private Datasets & Auth #︎
Some data we work with today is highly sensitive:
- In case of Biotech startups it may contain technology secrets, pre-patent discoveries, and financial data
- In case of GenAI - it may contain internal company materials used for inference.
So we extended Kamu Node to finally support private datasets and a flexible sharing system, based on a robust ReBAC authorization mechanism.
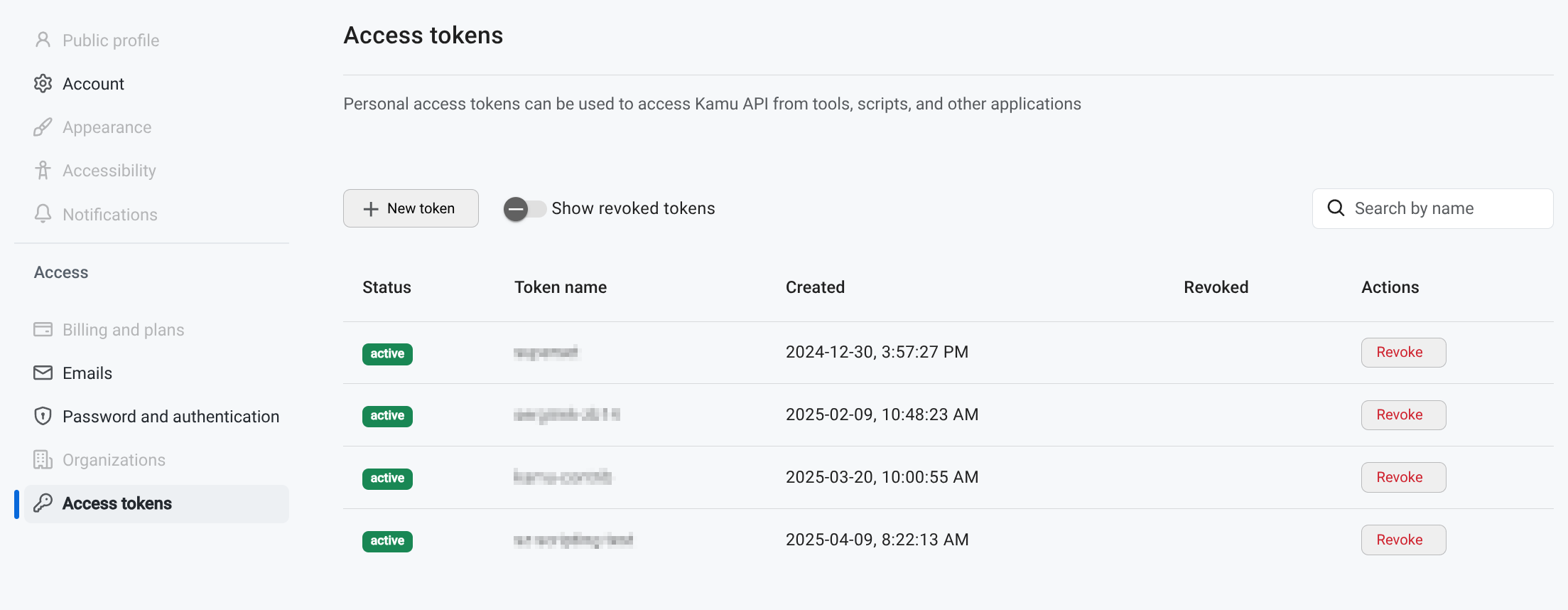
You can generate access tokens for scripting and automation.
CLI now supports OAuth2 Device Flow to authenticate with remote nodes.
And you can now authenticate with Kamu using cryptographic wallets - a major step we took towards personal data ownership in DeSci and DePIN use cases.
This is only the beginning of our privacy (structured transparency) roadmap.
Python Client #︎
We have released the first version of our official Python client library:
Now you can:
- Query data from Python scripts and notebook environments
- Query data from local workspaces and remote nodes
- Select between multiple SQL engines
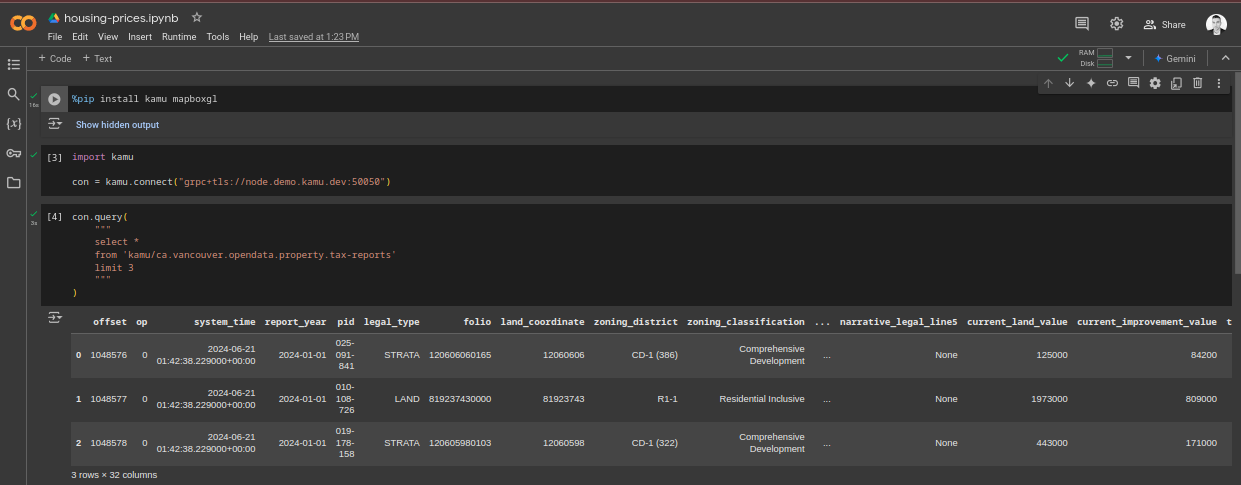
A minimal Jupyter notebook example is:
|
|
The client library is based on ADBC and FlightSQL - the most efficient protocols to transfer columnar data out there.
It works in any Python notebook environment - try running this example notebook in Google Colab.
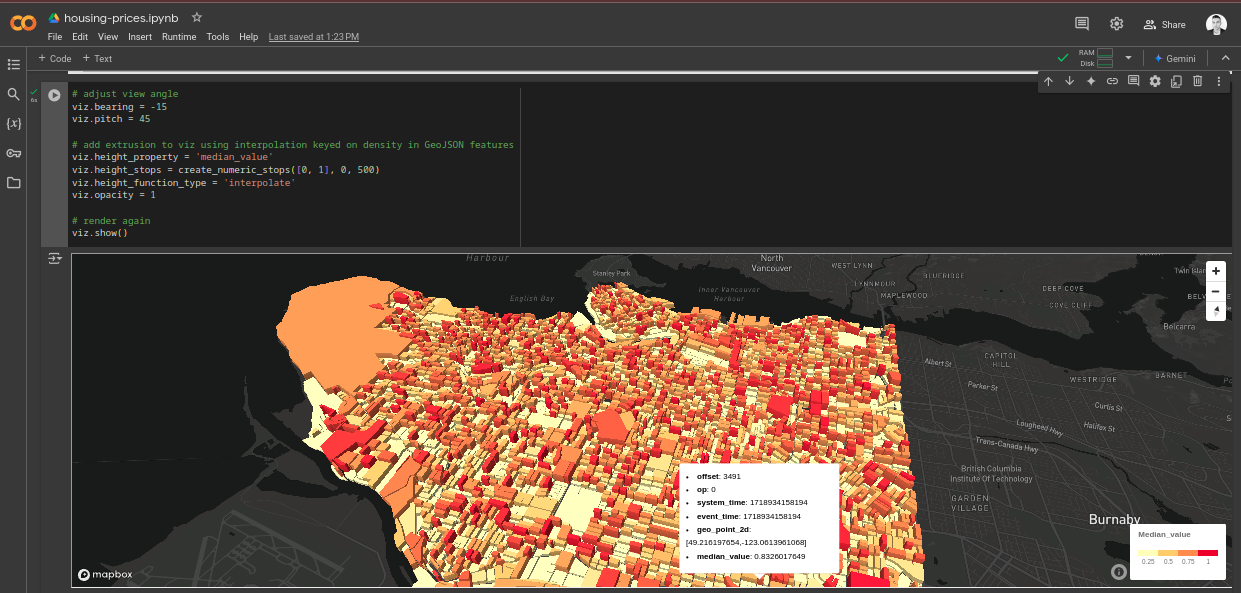
Verifiable Query API #︎
Imagine running an SQL query that aggregates gigabytes of data, or better yet - JOINs several huge datasets that belong to different organizations. The computations to deliver this result may span across several independent Kamu nodes, located in different countries and operated by different people with different incentives.
How can you trust such a result?
Enter Verifiable Query API. When you enable this mode - every query response from Kamu will be accompanied by a cryptographic proof of result validity.
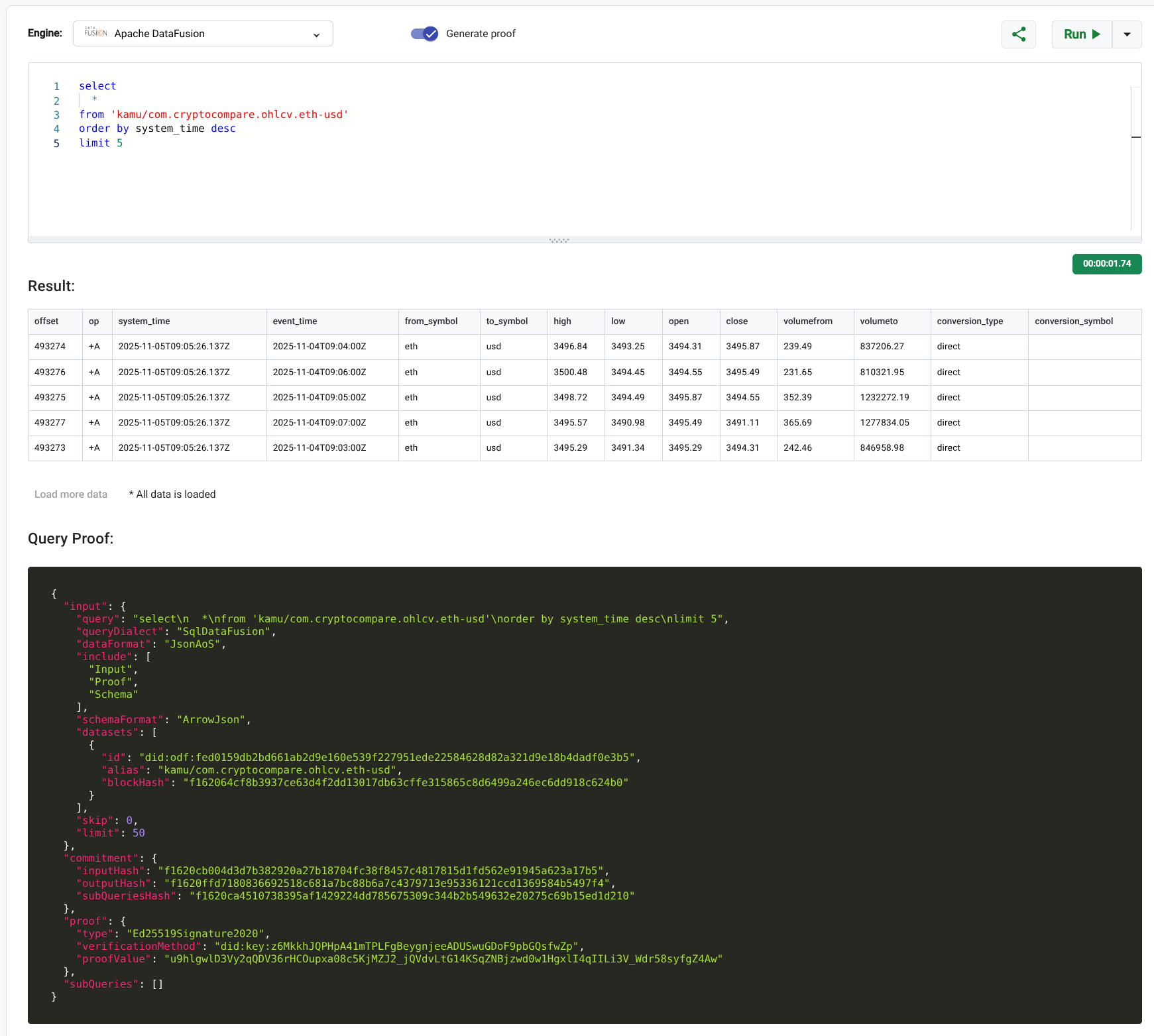
These proofs are succinct, much smaller than the result data itself (just a few kilobytes), but having them allows you to hold every participant of the entire supply chain that delivered you the response forever accountable for it.
Our novel Structured Recursive Commitments scheme allows to validate a response and assign blame to a specific actor of a multi-party collaboration.
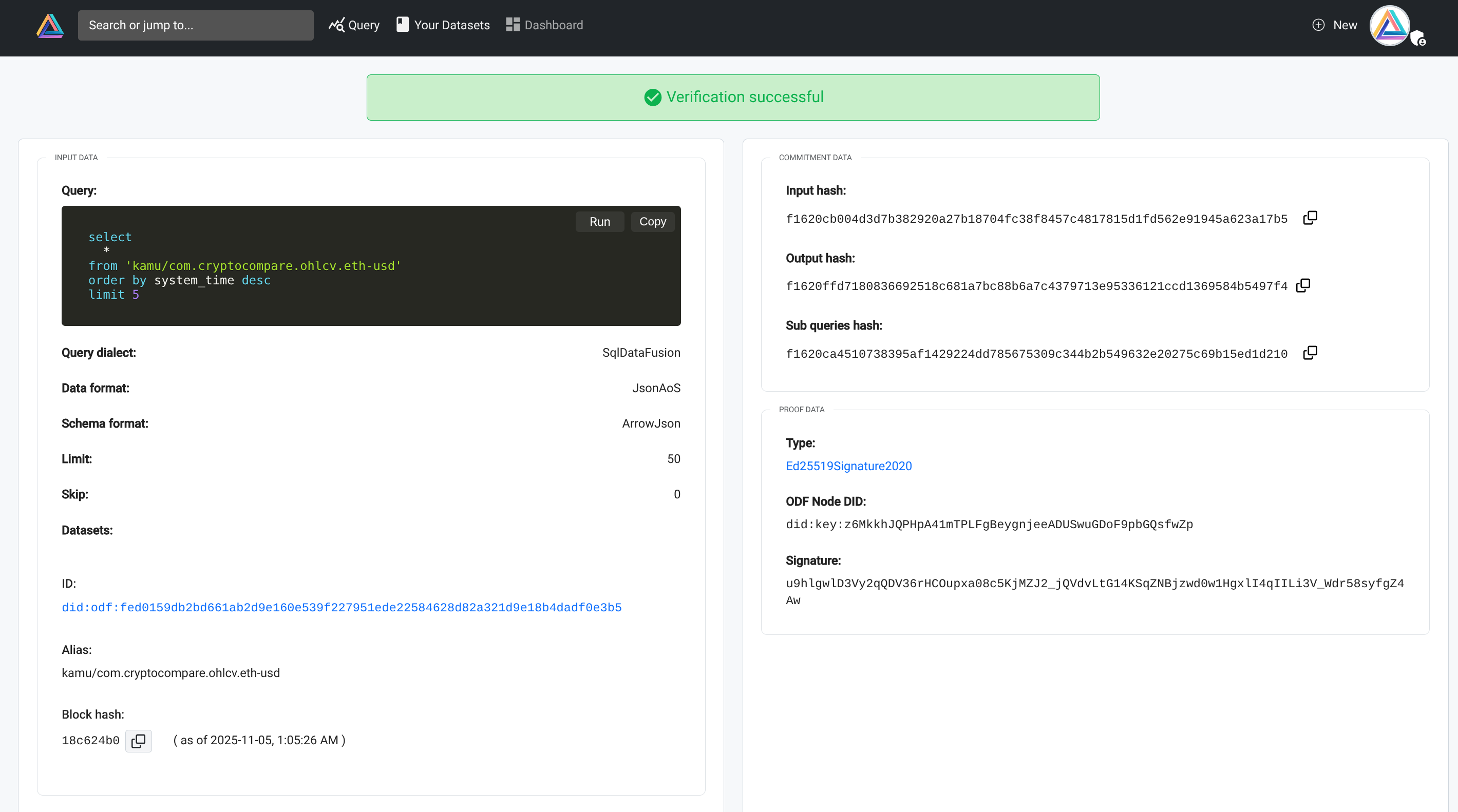
Currently we support an optimistic execution scheme (proofs based on signatures, determinism, and reproducibility), but in the near future will be expanding them to TEEs, and later to Zero Knowledge proofs.
This proof mechanism is fundamental to ODF Oracle - a system for querying data from blockchain smart contracts.
LLM Connectivity via MCP Server #︎
Kamu in collaboration with Brian have developed a new technique to connect LLMs to verifiable real-time factual data.
Oracle-Augmented Generation technique:
- Enables LLMs to execute complex analytical queries over large volumes of real-time data
- Makes AI answers auditable and far less prone to hallucination
- Offers full data supply chain provenance.
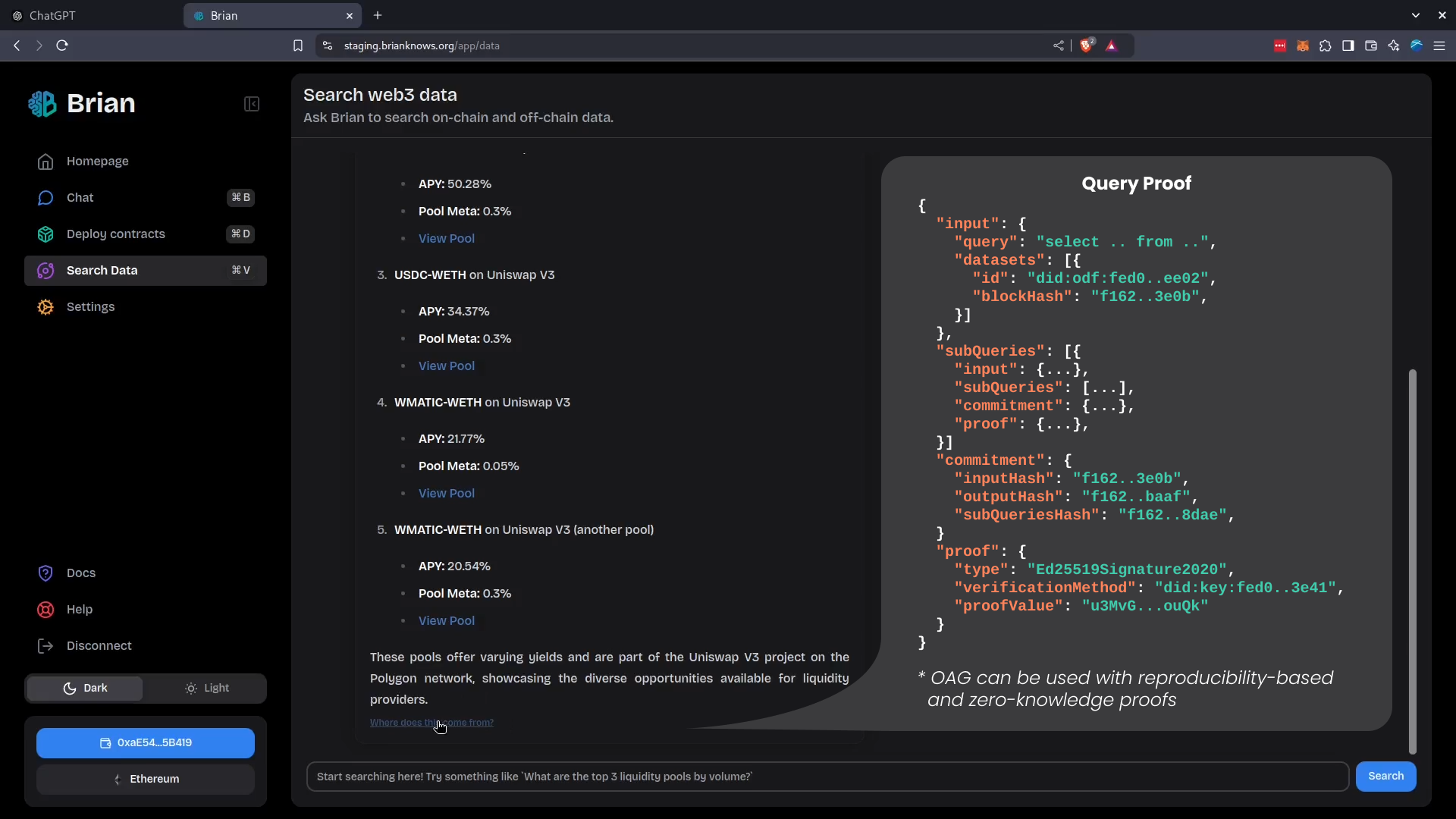
Proof saved alongside the agent's chat history
We believe this technique will be fundamental to granting AI agents more autonomy, without losing control and ability to reason about their actions.
It will likewise be fundamental in building an equitable data economy where owners of information and pipeline maintainers are fairly rewarded for their contributions in answering questions accurately.
The best thing is that you can use it just like any other MCP server.
Semantic Search #︎
First important step in our LLM connectivity technique was to narrow down the search space of what datasets can potentially answer a certain questions from thousands to a few dozens, not to overload LLM context window. We achieved this by implementing semantic search API to find most relevant datasets.
Metadata about the dataset like its description, schema, and example queries is converted into vector embeddings and stored in a vector database for efficient querying and ranking.
You can now enter free-form text in the search box to find datasets that are close to desired theme:

Database-backed Metadata Catalog #︎
ODF file format standardizes dataset layout on disk, allows datasets to be interoperably shared and replicated across different environments. But when datasets are in your Kamu Node - scanning metadata as individual files is not very efficient.

Structure of an ODF dataset
We introduced a new metadata catalog that acts as a write-through cache in Postgres and MariaDB databases. This is very similar to multiple metadata catalog implementations for formats like Apache Iceberg, but in our case stores the cryptographic metadata chain blocks, refs, dataset summaries and dependency graph, and a lot more.
This change dramatically improves performance of most operations. It also ensures atomic transactions, which are hard to achieve in pure-storage catalogs like S3.
Kamu CLI also benefited from these changes, as it is now using SQLite-based implementation of such catalog.
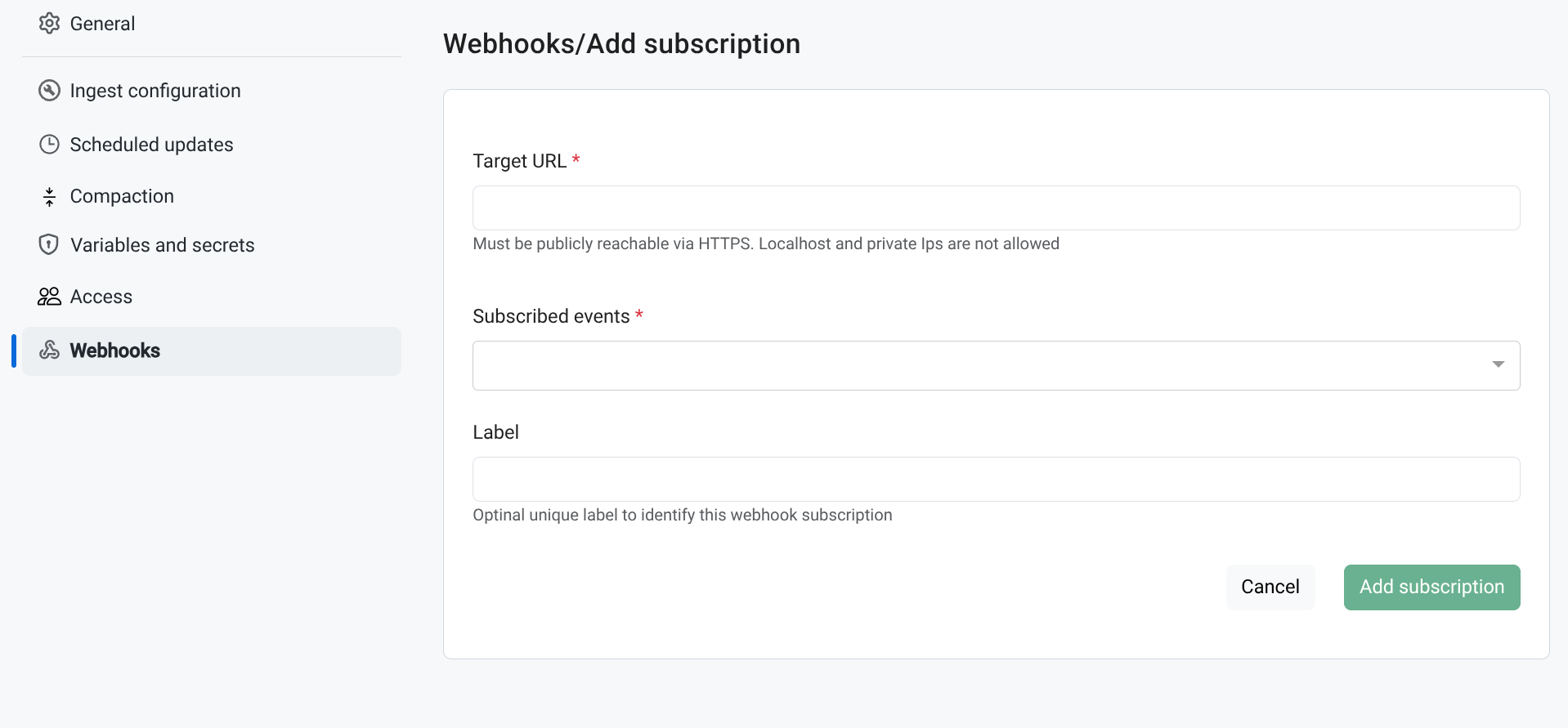
Webhooks #︎
As data moves through the pipelines in Kamu - there are multiple use-cases for changes in datasets to drive some automation. For this we have added full-fledged support for Webhook mechanism that supports message signatures (RFC 9421) and content digests (RFC 9530) for security.
Variables and Secrets #︎
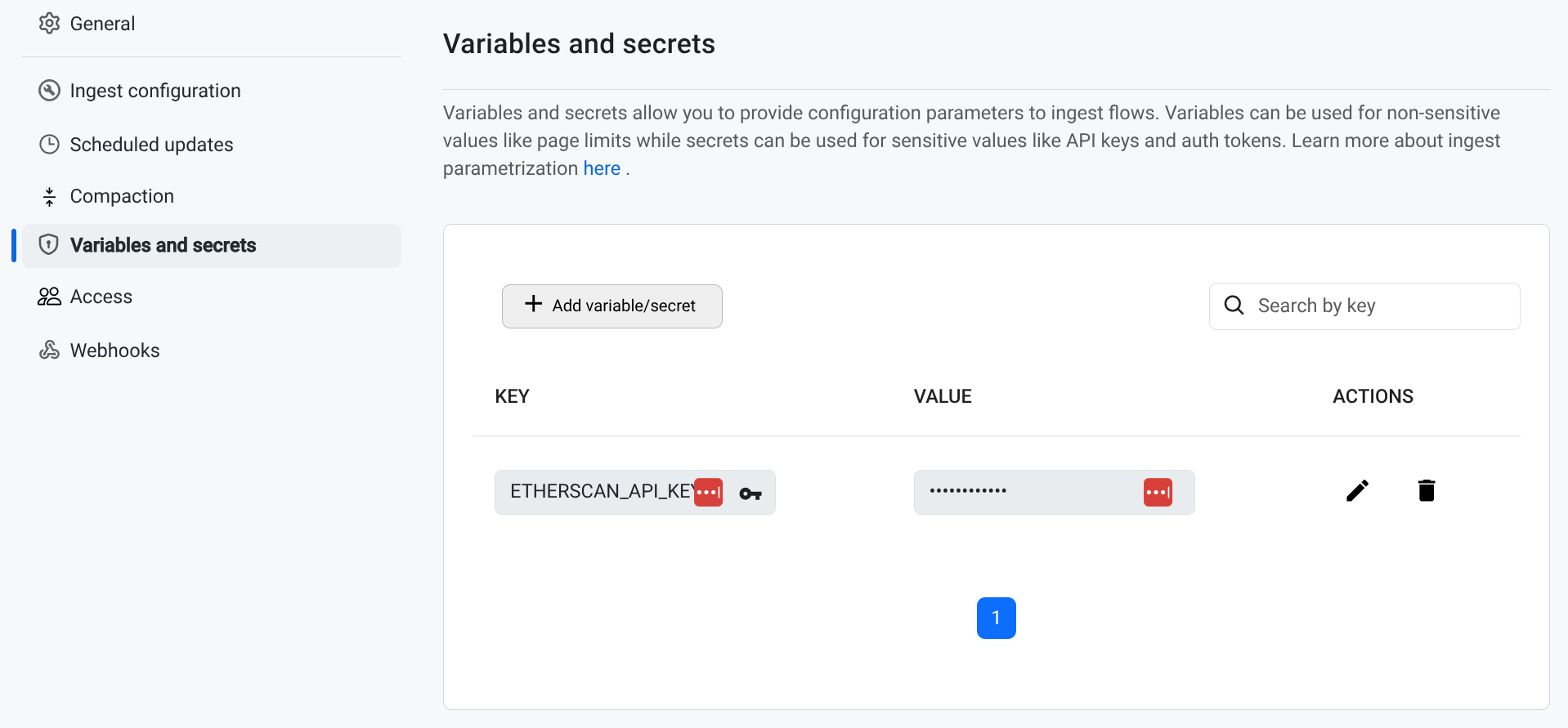
We added support for variables and secrets that can be passed down into ingestion tasks, making it easy to interact with data APIs that require some form of authorization. All secrets are stored securely encrypted.
Usability #︎
My (very biased) feeling is that we struck the right design and exact right combination of technologies to move the stagnating world of data into a new territory. As a software architect, never before have I seen so many pieces of the puzzle falling neatly together, even those that we have not at all anticipated.
Our biggest challenge admittedly will be making the product extremely easy to use. Accessibility, rapid feedback, and guiding users to right actions will be the key to undo the decades of dominance of the batch processing model.
A few highlights in this area include:
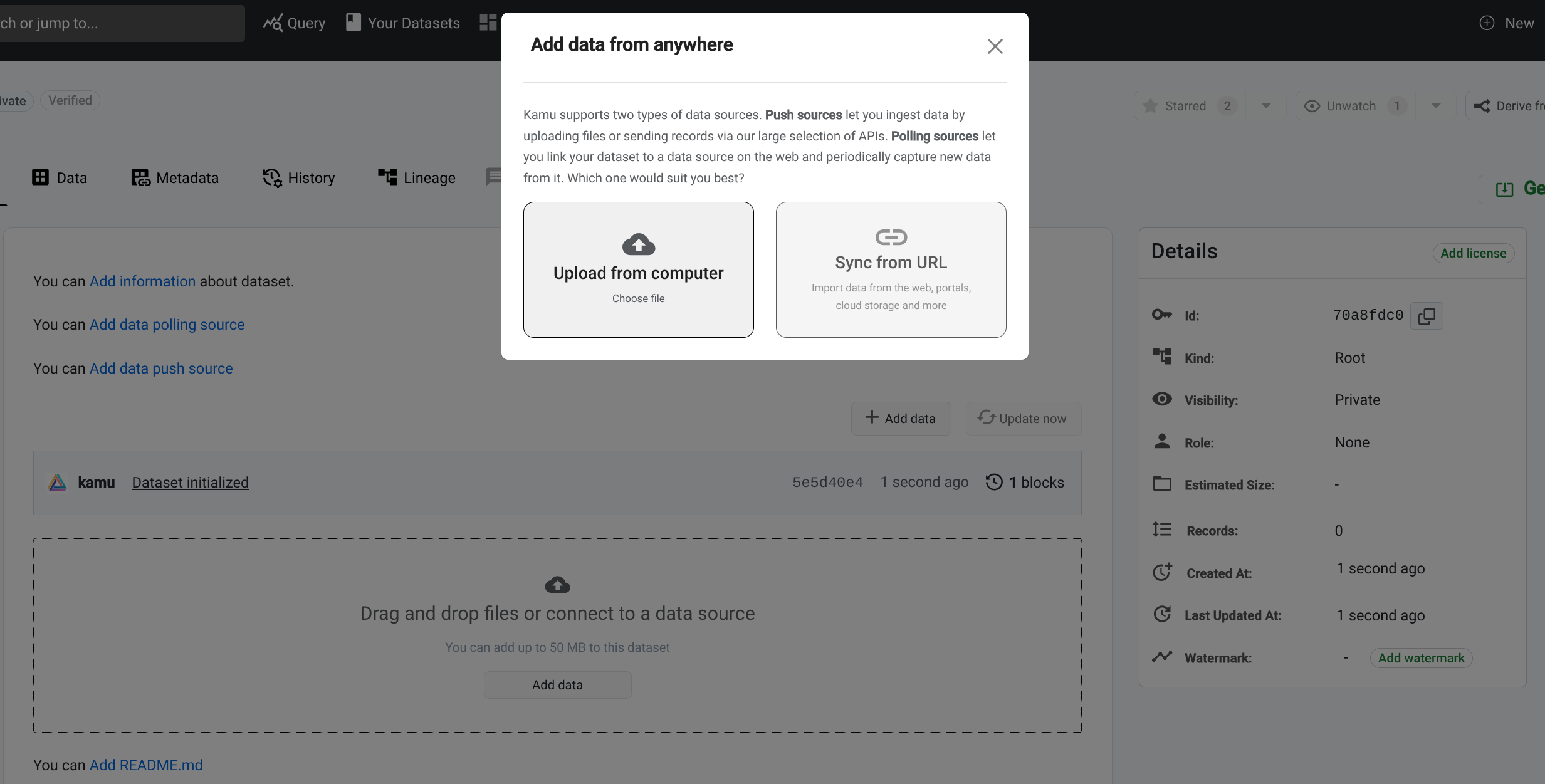
Ingestions via file uploads allows you to create root datasets by dragging & dropping files.
Email gateway support that will notify you about changes to your account and the state of your pipelines.
Documentation overhaul including:
- Much better structure of the documentation portal
- Built-in quick search
- Inclusion of ODF spec and metadata schemas reference
- RFC history
- Comprehensive Glossary with cross-linking of all terms throughout our docs and tutorials
- REST API reference documentation using OpenAPI
- New GraphQL playground
Core ODF Protocol #︎
The core protocol has been getting many cool improvements as well, too many to list.
Some highlights:
- More expressive dataset schema definitions
- Separation of ODF crates from Kamu implementation to help building more ODF-compatible clients
- Redesign of metadata traversal (
MetadataChainVisitor) that allows to express complex computations on dataset history while utilizing multiple layers of caching for efficient traversal - Projecting changelog history into a state snapshot using
to_table()UDTF - Hard compactions
- New
ChangelogStreamandUpsertStreammerge strategies
What’s Next? #︎
Our near-term roadmap includes:
- Securing future funding
- Improving dataset schema migrations
- Improving usability and shortening feedback loops
- Privacy-preserving queries and transformations using TEEs
- More declarative pipeline and resource management
- Further separation of ODF core libraries
- Integrating more engines
- System abuse prevention
Our focus will remain primarily on working closely with existing partners, but all improvements we make benefit Kamu Node’s functionality for everyone else.
We remain fully committed to build Kamu as local-first software, meaning everything you can do in Kamu Node you’ll be able to do locally with Kamu CLI, without sign-ups, accounts, and for free.
Thanks so much for reading, and huge thanks to our team for making all this happen. Start a conversation with us on Discord.
Till next time!

