- Executive Summary
- DERs everywhere!
- Energy’s data problem
- So is data a bottleneck for DERs?
- Conclusion
Executive Summary #︎
The energy sector is undergoing a fundamental shift. As solar, wind, batteries, and smart devices proliferate, generation and consumption are moving away from a handful of large centralized plants toward millions of small distributed resources - each one a potential participant in grid balancing, energy markets, and carbon accounting.
Managing a grid with a hundred large generators is fundamentally a different problem than managing one with a million small DERs. The bottleneck is no longer the hardware - it’s our ability to make sense of vast amounts of data: to observe, verify, share, and quickly act on the behavior of distributed resources, across organizational boundaries, in real time, at scale.
In this article we examine the specific ways current data infrastructure falls short - from vendor lock-ins and quadratic integration complexity, to privacy and accountability problems of multi-party data exchange - and the cascading effects these problems create that slow down the DER space. We will identify specific architectural gaps and propose a unified, sector-agnostic approach to address them.
DERs everywhere! #︎
With the proliferation of renewable power and cheaper batteries, the energy sector is undergoing a transformational change towards decentralization - towards DERs.
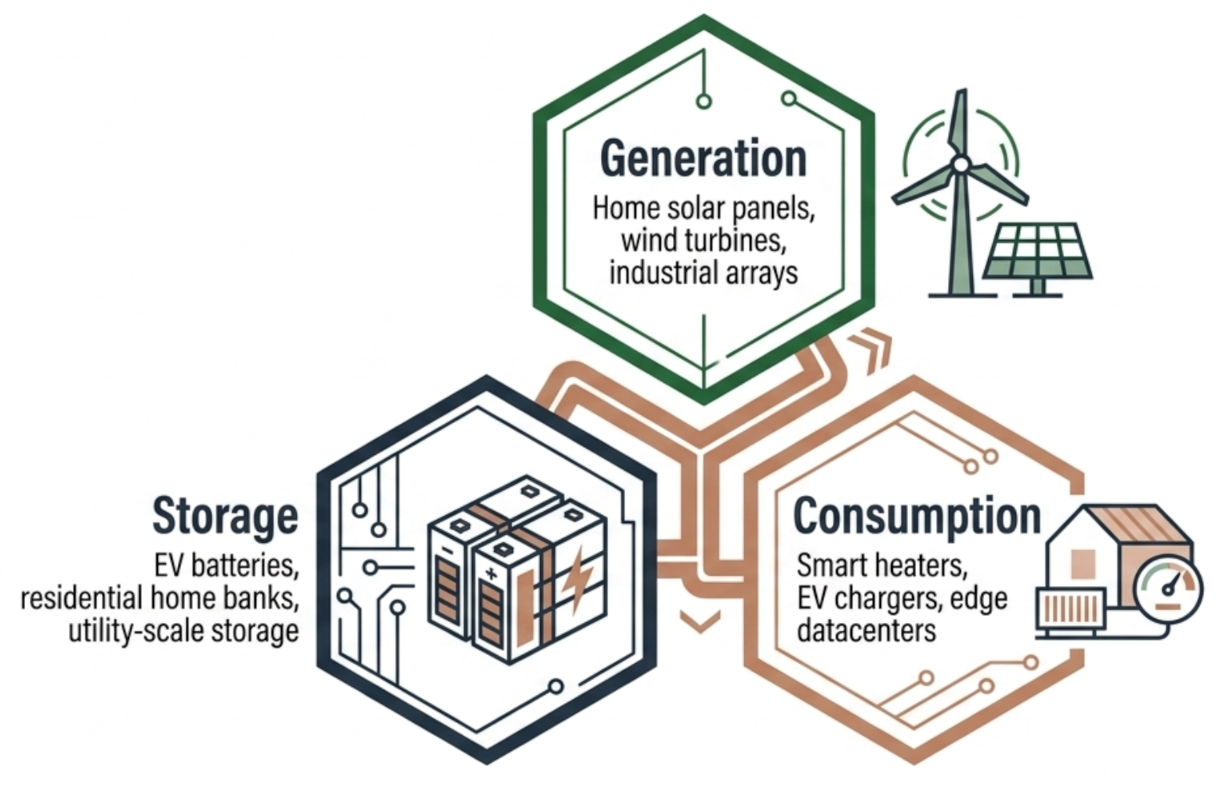
DER (Distributed Energy Resource) can refer to:
- Generation - from solar panels on your house, to a wind turbine, and industrial solar arrays
- Storage - from a car battery and residential home banks, to utility-scale battery storages
- Consumption - from your smart heater and EV charger to a small datacenter.
Energy sector is a big balancing act of generation and demand. Balancing requires a lot of coordination. Coordination in turn relies on a lot of data. Negative electricity prices and massive grid outages, which have become a common occurrence, show that this process is not working well, due to large generation forecast errors, curtailment, and output coordination issues.
DERs are exciting because they provide a solution:
- Abundant storage capacity that moves closer to consumers
- Consumption flexibility with smart chargers and devices, and much more.
To us, as data engineers, DERs are exciting because they require completely re-evaluating the data flows used to monitor and manage current infrastructure, how we integrate the massive number of small-scale devices into a common grid, and utilize all devices to maximize efficiency.
Energy’s data problem #︎
Let’s analyze the current data flows from several perspectives to identify gaps and opportunities to improve.
Ownership #︎
If you have any IoT devices in your home, you likely know the state of data ownership already. Every device manufacturer wants to tie you into their ecosystem and make you send data into some proprietary platform. You get a few quick dashboards out of the box, but if you want to later switch vendors, or your vendor discontinues their platform (very common in a competitive market) - you lose your data. You have to work quite hard to regain control over your data.
The same exact thing happens on a large scale. If you are building an industrial solar array - you buy inverters from some vendor, and those come with a subscription-based proprietary data collection and monitoring platforms.
We’re talking about a lot of data. A 10 MW array with 100 string inverters sampled every 5 seconds may produce over 2M data points per hour 1. So your monitoring stack quickly develops “data gravity” and becomes a big factor in locking you into one vendor.
⚠️ I should clarify that I don’t think hardware vendors are evil and aim to use data gravity as leverage. A few major hardware manufacturers I know said they would prefer not to develop their own data solutions at all, and see them as a distraction from their core business. The problem is that there hasn’t been any middle ground between niche “turn-key” data apps (a convenient product that users want) and a “build your own from a thousand pieces” infrastructure (that provides data sovereignty).
What can we do? #︎
There is a clear parallel between the current state of data and where software was a decade ago. Deploying and operating software was an arduous process that required bespoke integrations and tightly coupled you with your infrastructure provider. Kubernetes project created a new level of abstraction where software components could be packaged as standard-ish lego pieces and deployed in any cloud or on-prem environment, significantly reducing vendor lock-ins.
For convenience and sovereignty to co-exist in data we need two things:
- Ability to replicate our valuable data from any app to third-party storage for safe-keeping, or migrate it to another platform. Not a “data export” button that spit out a huge archive file in bespoke formats - a standard protocol to continuously move large volumes of structured data across company boundaries.
- Ability to transfer the data processing logic from one platform to another. The way you clean, aggregate, and enrich your data encodes hard-won domain knowledge about how to interpret raw device readings. Currently when switching to a different platform you are not migrating this logic - you’re rebuilding it, because the execution semantics between platform differ slightly in many ways.
Open Data Fabric (ODF) specification is our attempt to build “Kubernetes of data”. It’s a layer that wraps many open-source data storage and processing systems into “lego pieces” that compose well. Through standard formats it allows to efficiently replicate data between storages and systems in near-real-time. Thanks to standardized processing semantics it provides portability across implementations and environment - you can run the same pipeline on a laptop, edge server, or in a datacenter, using tools from different vendors.
Interoperability #︎
When an IoT manufacturer builds a data app, it’s more of a “toy” with a few functions than a “data platform” - a check mark in their feature completeness list needed to sell a device. There are no real incentives for them to bother with extensibility, storage diversity, data exports and backups, interoperability with other tools.
But the data these apps hoard has hundreds of potential uses - and you need interoperability to unlock them. If you have ever tried to implement things like smarter heating scheduling for your house, you know that it requires first spending at least a week to build an alternative pipeline to move data to a place where it can be used by scripts and other tools.
Same, again, repeats on a larger scale. Most data tools supplied by industrial hardware vendors come from a long legacy that focused only on monitoring and maintenance. As number of uses for same data keeps growing (see next section), you also end up having to build an alternative data pipeline, and at this scale you’ll need a whole data engineering team.
When there were only a handful of large utility companies, having a data team was not a big problem. But in the world of DERs this is no longer viable. Things like generation forecasting or predictive maintenance cannot remain “tools for the big players only”.
Even at a 10 MW array scale, deviating from the forecasted output by 5% on average can cost the company hundreds of thousands of dollars and 10-15% of annual revenue in imbalance penalties 2. No wonder that many solar developers spend years of engineering time on custom data stacks to achieve better forecasting.
The interoperability problem is arguably even more important on an inter-company level. When one firm builds flexibility into their EV chargers and another adds similar energy flexibility into smart heaters - we need common protocols for them to participate in scheduling optimization together. Every company today invents its own APIs, resulting in a O(n²) quadratic explosion of integration complexity.
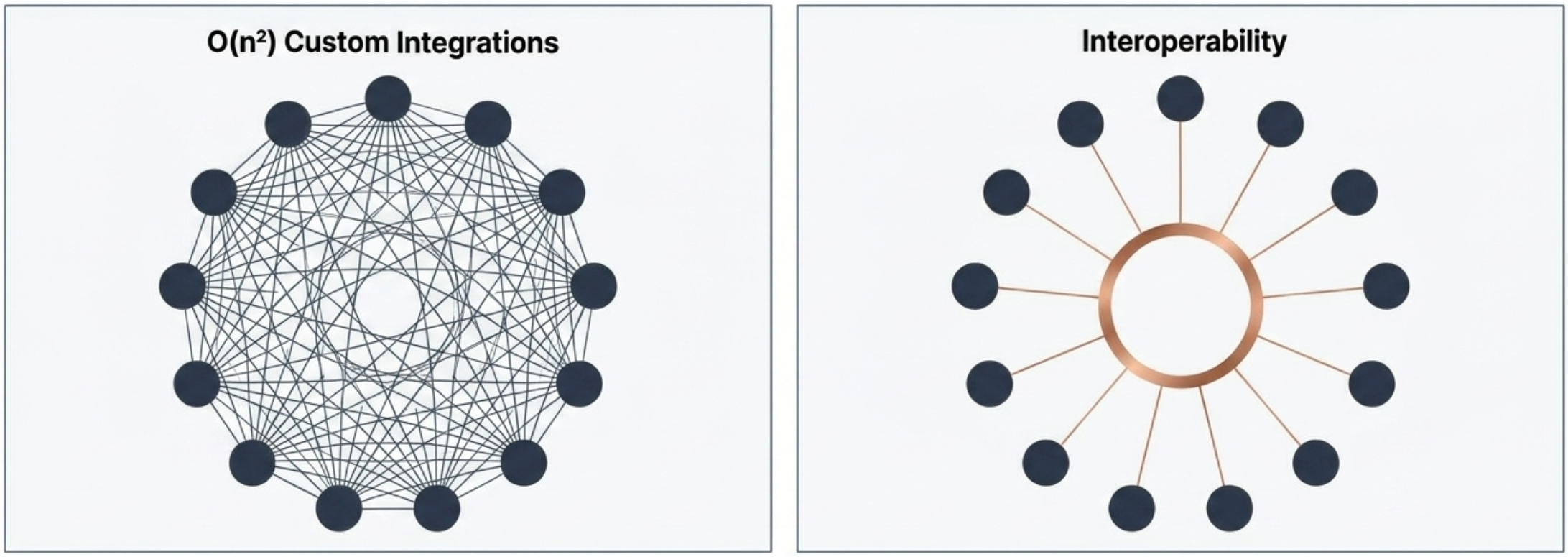
O(n²) complexity of custom integrations vs. interoperability
Energy sector has many mature standards, but as you’ll see in the next section, data that DERs generate needs to efficiently cross not only site, but industry and sector boundaries. And this goes both ways, as DER operators also require access to external (weather, financial, hardware costs) data to plan strategically.
What can we do? #︎
Existing energy data standards (Modbus, DNP3, OCPP etc.) bundle domain-specific semantics, wire formats, and network protocols into a single specification. This works well for device-to-device communication, but not for cross-domain interoperability.
We’re missing a layer that defines how historical and real-time information is stored and exchanged independently of semantics and network protocols. A data consumer receiving two feeds, one from a solar plant and one from a financial market, should only focus on domain aspects of each to correctly combine them. Everything else - how records are encoded, transferred, how updates are propagated - would be handled automatically. This is what Open Data Fabric spec defines.
The closest thing to this today is JSON APIs, but they fall short in many ways. Every API is highly custom - there’s no standard for how data is queried, filtered, aggregated, paginated, how updates are signaled, or how historical data is accessed, which means every integration is effectively built from scratch. Almost every real-world integration of several data sources ultimately involves first moving everything into an intermediate database before any actual analysis can begin. ODF is designed to make that intermediate step unnecessary.
This approach scales from capturing raw monitoring data, to feeding it to anomaly detection, to aggregating it for reporting and BI, to enriching it with external market, weather, and irradiance forecast data - all in a uniform way. Let’s see how this approach also scales when it comes to exchanging data with external parties.
Sharing and trading #︎
Imagine having data from thousands of home solar setups around the world - it would be hugely valuable! But you’d really struggle to find a buyer for data from just your house.
Similarly, data from a solar array has thousands of uses:
| Recipient | Purpose |
|---|---|
| Grid operators (ISOs/TSOs), VPPs | Grid balancing, scheduling |
| Corporate buyers / offtakers | PPA benchmarks & verification |
| Weather, irradiance forecasters | Improving forecast models |
| Traders | Price discovery, financial derivatives, insurance |
| Carbon and ESG markets | Disclosure, substantiating renewable energy claims |
| Hardware vendors | Operational efficiency and competitive research |
| Regulators | Oversight, planning |
| Academic research | All the above and more |
Many operators are waking up to the idea of their data being a valuable product on its own, but capturing this value when you run just one site is disproportionately hard. Finding a buyer, negotiating a complex contract and NDA, integrating and maintaining data delivery flows via portals, warehouses, FIX and Websocket APIs, is a lot of work outside of your core business. And this effort grows linearly with the number of recipients. That’s what we call a “small publisher dilemma”.
The energy sector is one of the few cases where data is so valuable that multiple “aggregator” companies exist that source it from individual sites to sell in bulk. They may offer you access to market-wide statistics in exchange, but in the end most value of your data is captured by aggregators.
What can we do? #︎
What if we flip the problem on its head and redesign the data infrastructure from “deliver-to-each-buyer” model to “publish-once” model. Instead of an operator maintaining separate integrations for every data consumer, the operator advertises a dataset on a public network, defines price, license, and access conditions including what level of aggregation is visible to whom - and any number of consumers can discover and access it through standard protocols. For operator the effort is constant no matter how many downstream consumers exist.
This changes the value dynamics of small datasets. If the publishing infrastructure allows the global community of researchers and data scientists to build derivative pipelines that combine data from many individual sites into higher-order data products - the operator’s data becomes easier to discover and consume, and exponentially more valuable. Every site operator automatically benefits from every subsequent site that joins the publishing network, without any extra work.
Critically, this doesn’t require sacrificing control: query patterns and aggregation rules defined at publish time let the operator control precisely what is visible at each level, and those rules are enforced by the infrastructure.
The economics also shift. Instead of aggregators capturing most value by virtue of being the only party with the engineering capacity to assemble and resell the data at scale - value is captured primarily by data owners. Overpriced integration pipelines will immediately invite competition from global community of data engineers.
Privacy and accountability #︎
When energy data is used in so many applications, it better be reliable. But how can we trust that a party delivers data that is real and accurate?
We could ask for disaggregated data and near-real-time delivery. Add device signing, and you’ll have robust protection against tampering.
But raw data is a major privacy and security concern:
- It exposes the map of your physical infrastructure and reveals when equipment fails
- Advertises your attack surface and when on-site personnel are present or absent
- Provides competitive intelligence about your performance and curtailment patterns for bidding behavior inference and PPA negotiation leverage.
So data needs to be shared selectively, with levels of anonymisation and aggregation. And this layer is always custom-built - yet another massive task for your data engineering team.
But if the data is processed and doesn’t come signed straight from a device - how can we be sure that it’s not synthetic, generated to make a quick buck, or that it’s not omitting some critical interval to cover something up?
In current approaches - we simply can’t. While revenue-grade metering with certified meters directly read by ISOs provides tamper-evident generation records for settlement - there is no such mechanism for the rest of the data. Financial market consumers don’t have any mechanism to keep providers accountable for API call responses. Data shared via some warehouse tables can be changed overnight without any trace. This makes data products overall much less valuable, and any doubts about the validity of some value or a chart require months of work to address.
What can we do? #︎
The accountability gap is a provenance problem - we need to prove that data we aggregated or anonymized for the sake of privacy actually corresponds to original raw device data. But how can we do this without revealing all raw data for audit?
Enter confidential computing. If data is cryptographically signed at the device and every subsequent processing step produces a cryptographic proof that the computation ran correctly on authentic inputs, then the trustworthiness of a derivative dataset can be confirmed without trusting the parties who handled it. A data consumer can independently verify that an aggregated or anonymized dataset is a faithful derivative of real device readings with no gaps, substitutions, or fabrications, regardless of how many processing steps or organizational boundaries it passed through.
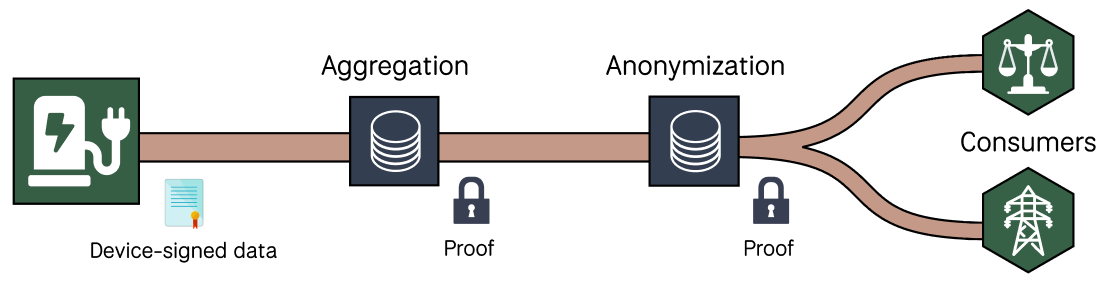
Anonimized data verifiable back to the original device readings
The implications for ESG markets are significant. Today carbon offsets or RECs are traceable only as far back as the reporting entity that submitted them to a registry. With device-level signing and verifiable computations, every certificate could be cryptographically linked back to the physical event that created it, like a certified flow rate meter measuring sequestration or carbon capture. This would make greenwashing and certificate fraud structurally difficult rather than merely illegal as it would require tampering the certified device itself rather simply changing data values anywhere in the downstream pipelines.
ODF seamlessly integrates modern confidential computing techniques like TEEs and Zero-Knowledge Proofs into data processing pipelines, with pilot projects conducted in the carbon offsets market.
Recency, latency, automation #︎
In our team we often discuss how power-hungry AI workloads and cryptocurrency mining could be instantaneously dispatched to datacenters in areas where energy prices go negative as a perfect dump load. But a quick reality check shows that most operators today still handle day-ahead scheduling manually. Even if ML forecasting is used - it still mostly runs on the same 24-hour schedule and with manual sign-offs. There’s such a big gap between where we want to be with DERs and where we are right now…
Unlocking the potential of DERs will require:
- High degree of human-out-of-the-loop automation – to push latency to minutes/seconds
- High degree of traceability and auditability – to debug and gain confidence in said automation.
The current state of data tooling just doesn’t cut it. Outside of monitoring stacks, most tools operate on a fundamentally batch-oriented model — jobs are scheduled to run at fixed intervals, reprocess all data from scratch, at certain cutoff times, producing outputs that are stale before they’re consumed. No matter how much you automate - this model requires a lot of care around execution order, ensuring consistency across datasets that were frozen at different moments. A human has to be in the loop to maintain this extremely fragile machinery and to recover it after failures.
What can we do? #︎
Temporal processing - a new computational model alternative to batch - treats all pipelines as continuous flows where each processing step produces outputs incrementally as new data arrives, with the infrastructure guaranteeing consistency and execution order automatically. It’s like switching from algebra to calculus - a better way to express computations that involve passage of time. It isn’t just a latency improvement - it’s the only way to make genuine human-out-of-the-loop automation possible.

Batch flows requiring constant human attention

Temporal flows are configured once and run autonomously
If we ever hope to meaningfully track ESG scope 1, 2, and 3 emissions - across an operator’s own assets, their energy purchases, and their supply chain - and do so without needing an army of specialized accountants crunching numbers day and night - we need to build temporal pipelines that can be reviewed, certified, and continuously improved. Any operator should be able to reuse such pipelines like an open template - plug in their monitoring inputs, and get output data for disclosures at minimal cost of compliance.
Temporal processing combined with confidential computing would make ESG disclosures both verifiable and privacy-preserving.
Fragmentation #︎
Renewable energy certificate registries (aka REC, GO, REGO) is a consequential example of data fragmentation problem. Globally, RECs exist in dozens of incompatible regional systems 3 - each with its own data model, eligibility rules, temporal granularity, and identifier namespace. These registries don’t interoperate. A corporate buyer with operations across multiple continents must manually reconcile fundamentally incompatible certificate schemas, rely on intermediaries to convert certificates across registry boundaries - a process that is slow, expensive, and administratively rather than technically verified - and trust that bilateral agreements between registries prevent the same megawatt-hour from being claimed twice in two different markets.
The result is that the global renewable energy market runs on a foundation of administrative trust and manual reconciliation rather than technical verifiability, which limits how sophisticated it can become: real-time certificate markets, automated ESG reporting, and meaningful participation by small DER operators are all structurally out of reach until a common interoperability layer exists beneath the registries.
What can we do? #︎
Many blockchain-based solutions tried to address the registry fragmentation problem. Decentralized tamper-proof ledger sounds like a natural fit at first, but in practice, even specialized enterprise blockchains struggle with large volumes of data - they are designed for transactional rather than analytical processing. As DER space moves from high granularity assets (1 REC = 1 MWh) and infrequent settlements to more real-time interactions - single-ledger model would face scaling issues. And all data would still need to be copied into databases and lakehouse tools to be searchable, queriable, and interoperate with BI and data science tools.
A conventional SQL lakehouse architecture, on the other hand, is well understood and widely deployed. A cryptographic verifiability layer we discussed above can ensure that the data that lands into regional registries is trustworthy. Thanks to tamper-proof properties, not even registry admins will be able to modify it without a trace.
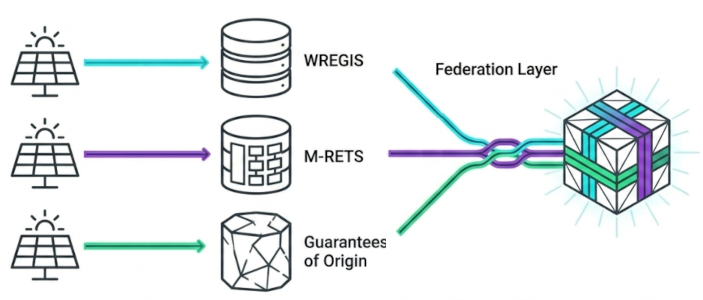
Federated registry of verifiable renewable energy certificates
Through a layer of federation, data from multiple registries can be harmonized and integrated together, and made easily available and efficient to query. Such integration pipelines can exist purely as code that deterministically reconstructs the dataset. It does not need to be governed by an authoritative body. It doesn’t event need any infrastructure! It can be maintained as a pure open-source initiative.
In this model every registry will retain full autonomy of evolving their data schemas, while federated pipelines will provide them an instant feedback on how their changes affect the harmonization layer and whether they break downstream consumers. The whole system will become more uniform over time by the nature of improved visibility.
So is data a bottleneck for DERs? #︎
There are many obstacles to DER adoption, and data infrastructure will likely not going to be on top of any operator’s list of bottlenecks. But viewing data merely “as one problem among many” understates how deeply data problems compound the others.
| Problem | Compounding role of data |
|---|---|
| Interconnection queue backlogs | Utilities and grid operators lack real-time visibility and forecasting confidence to approve DER interconnections quickly — approving a new resource is riskier when you can’t reliably model how it will behave alongside thousands of other small assets. |
| Utility resistance to VPPs | Is not simple institutional conservatism — but a response to genuine loss of observability and control. A utility that managed a handful of large predictable generators now faces millions of small behaviorally complex resources it can barely see and cannot reliably dispatch. |
| Regulatory hesitancy | Regulators can’t verify that a proposed DER will perform as modeled, forcing conservative assumptions and lengthy review processes to compensate for uncertainty. Auditable verifiable performance data would directly reduce that uncertainty. |
| Permitting and siting delays | Project approval requires demonstrating how a proposed asset will behave at a specific location. Without performance data from comparable deployed assets, reviewers fall back on conservative assumptions and safety margins. Accessible data from similar assets would help shift review from assumption-based to evidence-based. |
| Capital cost of hardware | Financing costs rise when lenders can’t get reliable standardized performance data to underwrite against. Absence of interoperable data standards means every project requires custom integration work that adds to the costs. |
These problems scale nonlinearly with DER proliferation and the O(n²) integration complexity becomes unmanageable at millions of small assets.
Conclusion #︎
The negative electricity prices and grid failures aren’t engineering failures - they’re coordination failures. The physics of renewable generation is well understood. The hardware to store and dispatch it is getting cheaper. What’s missing is the connective tissue: the ability to observe, verify, and act on the behavior of millions of distributed resources in real time, across organizational and jurisdictional boundaries. Preferably without armies of engineers needing to maintain it like a giant Rube Goldberg machine.
The problems we’ve described — vendor lock-in, quadratic integration complexity, the small publisher dilemma, the accountability gap, registry fragmentation - look like separate issues when viewed in isolation. But they share a common root: the absence of a sector-agnostic layer that handles how data is managed, processed, and exchanged independently of what the data means or which domain it comes from. Every sector that has developed such a layer - compute infrastructure with Kubernetes, package distribution with language registries, web communication with HTTP - has seen coordination costs collapse and innovation accelerate. Data infrastructure hasn’t had its equivalent yet.
When it does, a different set possibilities will open. A small solar operator publishes monitoring data once and reaches forecasters, insurers, researchers, and carbon markets without maintaining individual relationships with any of them. A utility approving a new DER interconnection has auditable, verifiable performance history from comparable assets rather than conservative assumptions based on manufacturer specs. A corporate buyer retiring a renewable energy certificate can verify its provenance back to a signed device record rather than trusting a chain of administrative reports. An ESG disclosure that currently requires a quarterly accounting exercise runs continuously and updates automatically as new generation data arrives. A grid operator dispatching thousands of EV batteries during a frequency event has sub-second verified telemetry from each one rather than stale batch reports.
None of these require new hardware or new physics. They require data infrastructure that treats verifiability, interoperability, and automation as first-class properties rather than afterthoughts.
Open Data Fabric is our attempt to specify this layer - open sector-agnostic spec, and already in use in biotech, finance, and IoT contexts. We think energy is where it’s needed most urgently, and we’d welcome the conversation with anyone working in this problem space.
-
10 MW ÷ 100 kW inverters × ~30 Modbus tags × 3,600s / 5s = 2.16M of raw records per hour prior to aggregation. ↩︎
-
Solar forecast errors of 5% nMAE are typical for sites without calibrated plant models [NREL]. In CAISO’s settlement structure deviations are settled at a 10% penalty multiplier above or below real-time prices [CAISO BPM]*. Figure is highly ISO-dependent. ↩︎
-
WREGIS in the western US, M-RETS in the midwest, GATS in PJM, Guarantees of Origin in the EU, I-RECs for international markets, and many more. ↩︎